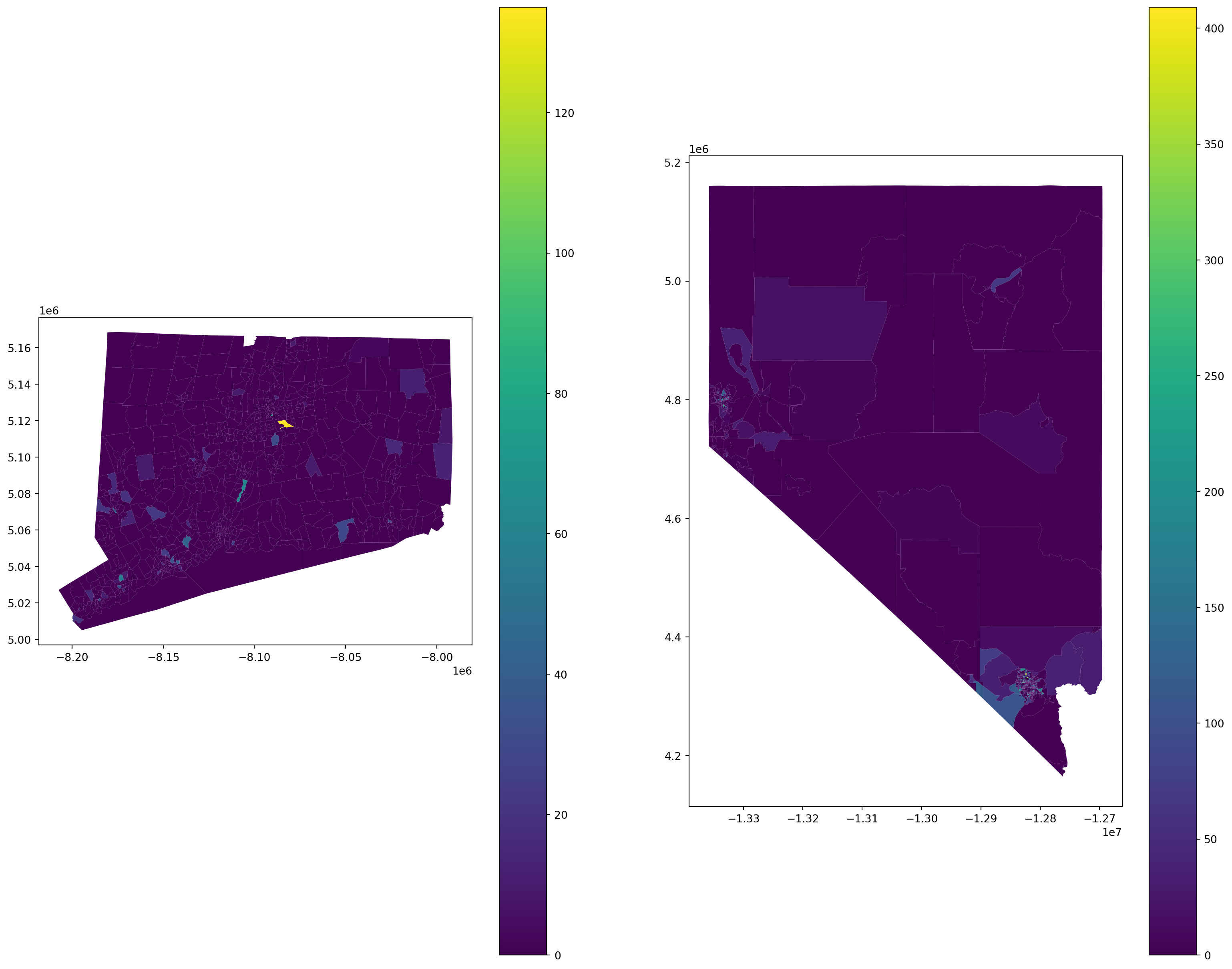
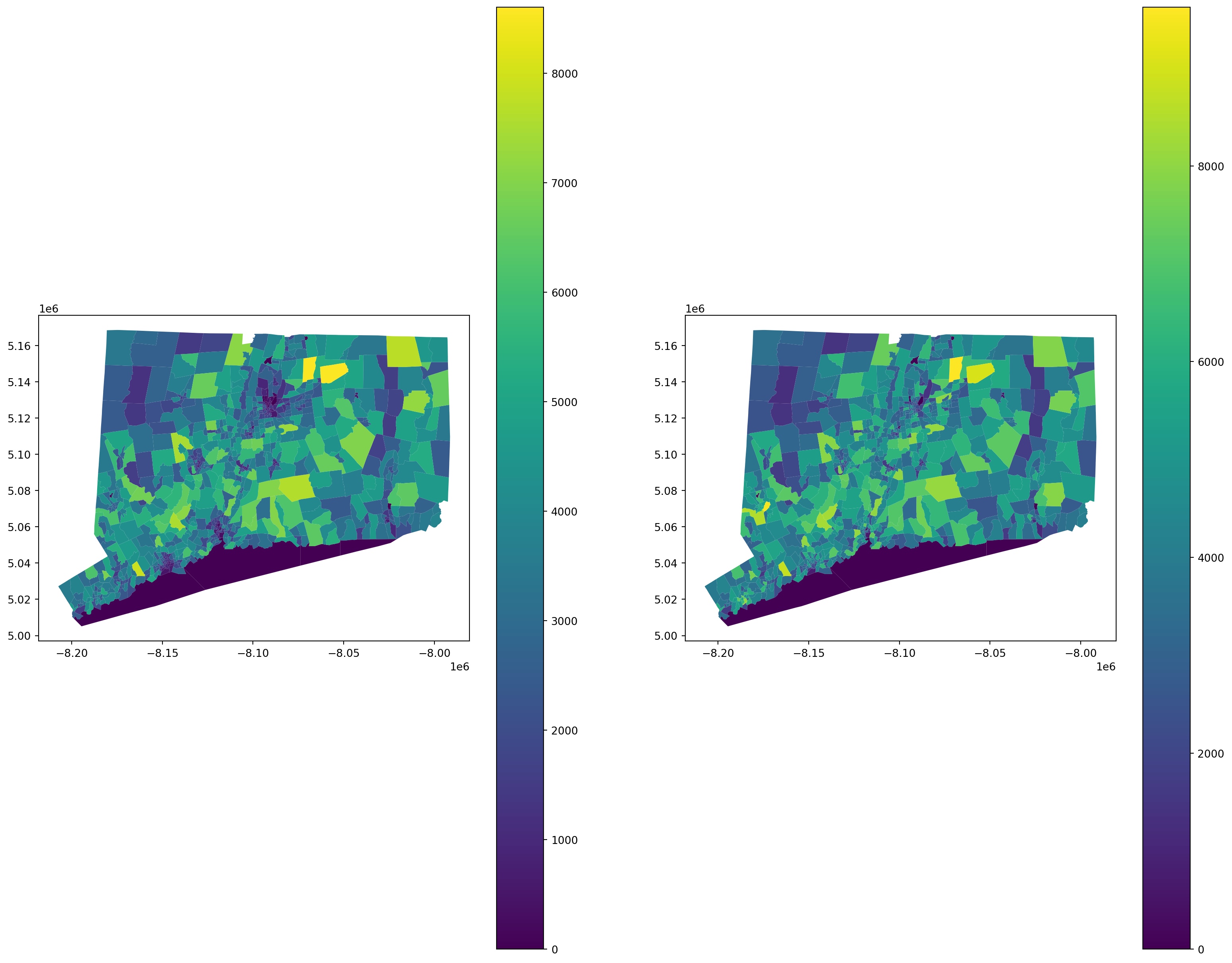
description \
table_name
B05010 RATIO OF INCOME TO POVERTY LEVEL IN THE PAST 1...
B06012 PLACE OF BIRTH BY POVERTY STATUS IN THE PAST 1...
B07012 GEOGRAPHICAL MOBILITY IN THE PAST YEAR BY POVE...
B07412 GEOGRAPHICAL MOBILITY IN THE PAST YEAR BY POVE...
B08122 MEANS OF TRANSPORTATION TO WORK BY POVERTY STA...
B08522 MEANS OF TRANSPORTATION TO WORK BY POVERTY STA...
B10059 POVERTY STATUS IN THE PAST 12 MONTHS OF GRANDP...
B13010 WOMEN 15 TO 50 YEARS WHO HAD A BIRTH IN THE PA...
B14006 POVERTY STATUS IN THE PAST 12 MONTHS BY SCHOOL...
B16009 POVERTY STATUS IN THE PAST 12 MONTHS BY AGE BY...
B17001 POVERTY STATUS IN THE PAST 12 MONTHS BY SEX BY...
B17003 POVERTY STATUS IN THE PAST 12 MONTHS OF INDIVI...
B17004 POVERTY STATUS IN THE PAST 12 MONTHS OF INDIVI...
B17005 POVERTY STATUS IN THE PAST 12 MONTHS OF INDIVI...
B17006 POVERTY STATUS IN THE PAST 12 MONTHS OF RELATE...
B17007 POVERTY STATUS IN THE PAST 12 MONTHS OF UNRELA...
B17009 POVERTY STATUS BY WORK EXPERIENCE OF UNRELATED...
B17010 POVERTY STATUS IN THE PAST 12 MONTHS OF FAMILI...
B17012 POVERTY STATUS IN THE PAST 12 MONTHS OF FAMILI...
B17013 POVERTY STATUS IN THE PAST 12 MONTHS OF FAMILI...
B17014 POVERTY STATUS IN THE PAST 12 MONTHS OF FAMILI...
B17015 POVERTY STATUS IN THE PAST 12 MONTHS OF FAMILI...
B17016 POVERTY STATUS IN THE PAST 12 MONTHS OF FAMILI...
B17017 POVERTY STATUS IN THE PAST 12 MONTHS BY HOUSEH...
B17018 POVERTY STATUS IN THE PAST 12 MONTHS OF FAMILI...
B17019 POVERTY STATUS IN THE PAST 12 MONTHS OF FAMILI...
B17020 POVERTY STATUS IN THE PAST 12 MONTHS BY AGE
B17021 POVERTY STATUS OF INDIVIDUALS IN THE PAST 12 M...
B17022 RATIO OF INCOME TO POVERTY LEVEL IN THE PAST 1...
B17023 POVERTY STATUS IN THE PAST 12 MONTHS OF FAMILI...
B17024 AGE BY RATIO OF INCOME TO POVERTY LEVEL IN THE...
B17025 POVERTY STATUS IN THE PAST 12 MONTHS BY NATIVITY
B17026 RATIO OF INCOME TO POVERTY LEVEL OF FAMILIES I...
B22003 RECEIPT OF FOOD STAMPS/SNAP IN THE PAST 12 MON...
B23024 POVERTY STATUS IN THE PAST 12 MONTHS BY DISABI...
B29003 CITIZEN, VOTING-AGE POPULATION BY POVERTY STATUS
B99171 ALLOCATION OF POVERTY STATUS IN THE PAST 12 MO...
B99172 ALLOCATION OF POVERTY STATUS IN THE PAST 12 MO...
C17002 RATIO OF INCOME TO POVERTY LEVEL IN THE PAST 1...
C18130 AGE BY DISABILITY STATUS BY POVERTY STATUS
C18131 RATIO OF INCOME TO POVERTY LEVEL IN THE PAST 1...
C21007 AGE BY VETERAN STATUS BY POVERTY STATUS IN THE...
C27016 HEALTH INSURANCE COVERAGE STATUS BY RATIO OF I...
C27017 PRIVATE HEALTH INSURANCE BY RATIO OF INCOME TO...
C27018 PUBLIC HEALTH INSURANCE BY RATIO OF INCOME TO ...
columns
table_name
B05010 [B05010_001E, B05010_002E, B05010_003E, B05010...
B06012 [B06012_001E, B06012_002E, B06012_003E, B06012...
B07012 [B07012_001E, B07012_002E, B07012_003E, B07012...
B07412 [B07412_001E, B07412_002E, B07412_003E, B07412...
B08122 [B08122_001E, B08122_002E, B08122_003E, B08122...
B08522 [B08522_001E, B08522_002E, B08522_003E, B08522...
B10059 [B10059_001E, B10059_002E, B10059_003E, B10059...
B13010 [B13010_001E, B13010_002E, B13010_003E, B13010...
B14006 [B14006_001E, B14006_002E, B14006_003E, B14006...
B16009 [B16009_001E, B16009_002E, B16009_003E, B16009...
B17001 [B17001_001E, B17001_002E, B17001_003E, B17001...
B17003 [B17003_001E, B17003_002E, B17003_003E, B17003...
B17004 [B17004_001E, B17004_002E, B17004_003E, B17004...
B17005 [B17005_001E, B17005_002E, B17005_003E, B17005...
B17006 [B17006_001E, B17006_002E, B17006_003E, B17006...
B17007 [B17007_001E, B17007_002E, B17007_003E, B17007...
B17009 [B17009_001E, B17009_002E, B17009_003E, B17009...
B17010 [B17010_001E, B17010_002E, B17010_003E, B17010...
B17012 [B17012_001E, B17012_002E, B17012_003E, B17012...
B17013 [B17013_001E, B17013_002E, B17013_003E, B17013...
B17014 [B17014_001E, B17014_002E, B17014_003E, B17014...
B17015 [B17015_001E, B17015_002E, B17015_003E, B17015...
B17016 [B17016_001E, B17016_002E, B17016_003E, B17016...
B17017 [B17017_001E, B17017_002E, B17017_003E, B17017...
B17018 [B17018_001E, B17018_002E, B17018_003E, B17018...
B17019 [B17019_001E, B17019_002E, B17019_003E, B17019...
B17020 [B17020_001E, B17020_002E, B17020_003E, B17020...
B17021 [B17021_001E, B17021_002E, B17021_003E, B17021...
B17022 [B17022_001E, B17022_002E, B17022_003E, B17022...
B17023 [B17023_001E, B17023_002E, B17023_003E, B17023...
B17024 [B17024_001E, B17024_002E, B17024_003E, B17024...
B17025 [B17025_001E, B17025_002E, B17025_003E, B17025...
B17026 [B17026_001E, B17026_002E, B17026_003E, B17026...
B22003 [B22003_001E, B22003_002E, B22003_003E, B22003...
B23024 [B23024_001E, B23024_002E, B23024_003E, B23024...
B29003 [B29003_001E, B29003_002E, B29003_003E]
B99171 [B99171_001E, B99171_002E, B99171_003E, B99171...
B99172 [B99172_001E, B99172_002E, B99172_003E, B99172...
C17002 [C17002_001E, C17002_002E, C17002_003E, C17002...
C18130 [C18130_001E, C18130_002E, C18130_003E, C18130...
C18131 [C18131_001E, C18131_002E, C18131_003E, C18131...
C21007 [C21007_001E, C21007_002E, C21007_003E, C21007...
C27016 [C27016_001E, C27016_002E, C27016_003E, C27016...
C27017 [C27017_001E, C27017_002E, C27017_003E, C27017...
C27018 [C27018_001E, C27018_002E, C27018_003E, C27018...