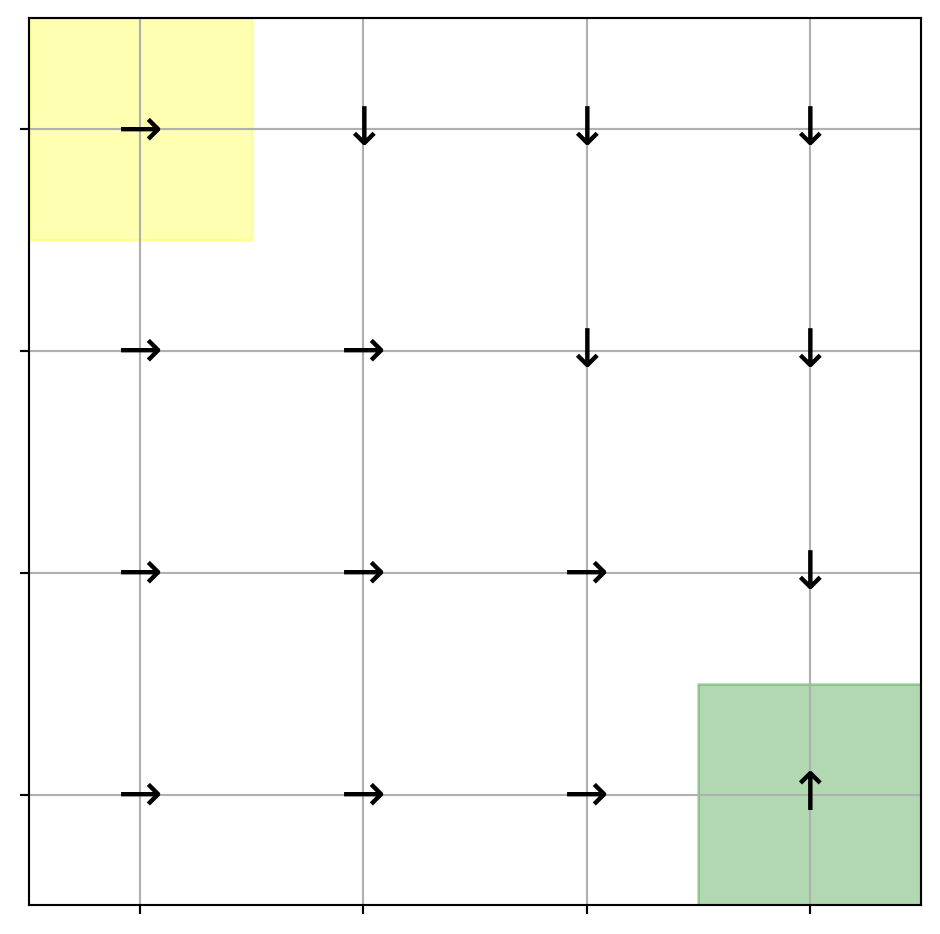
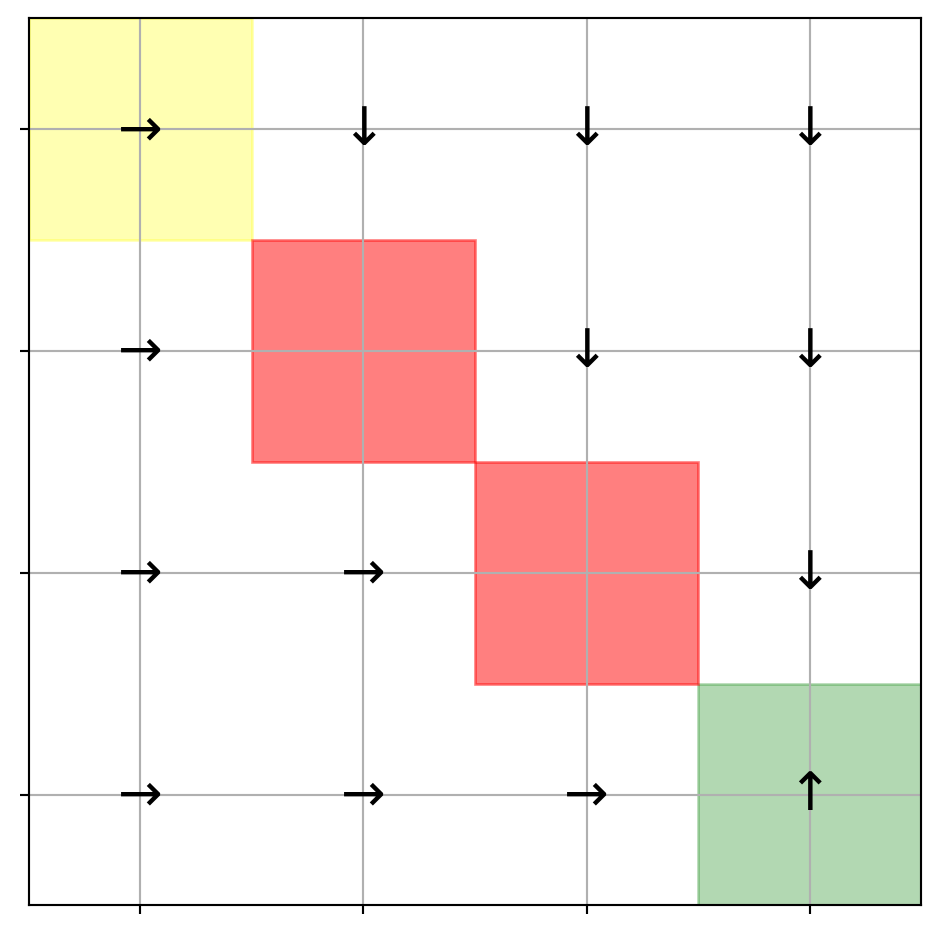
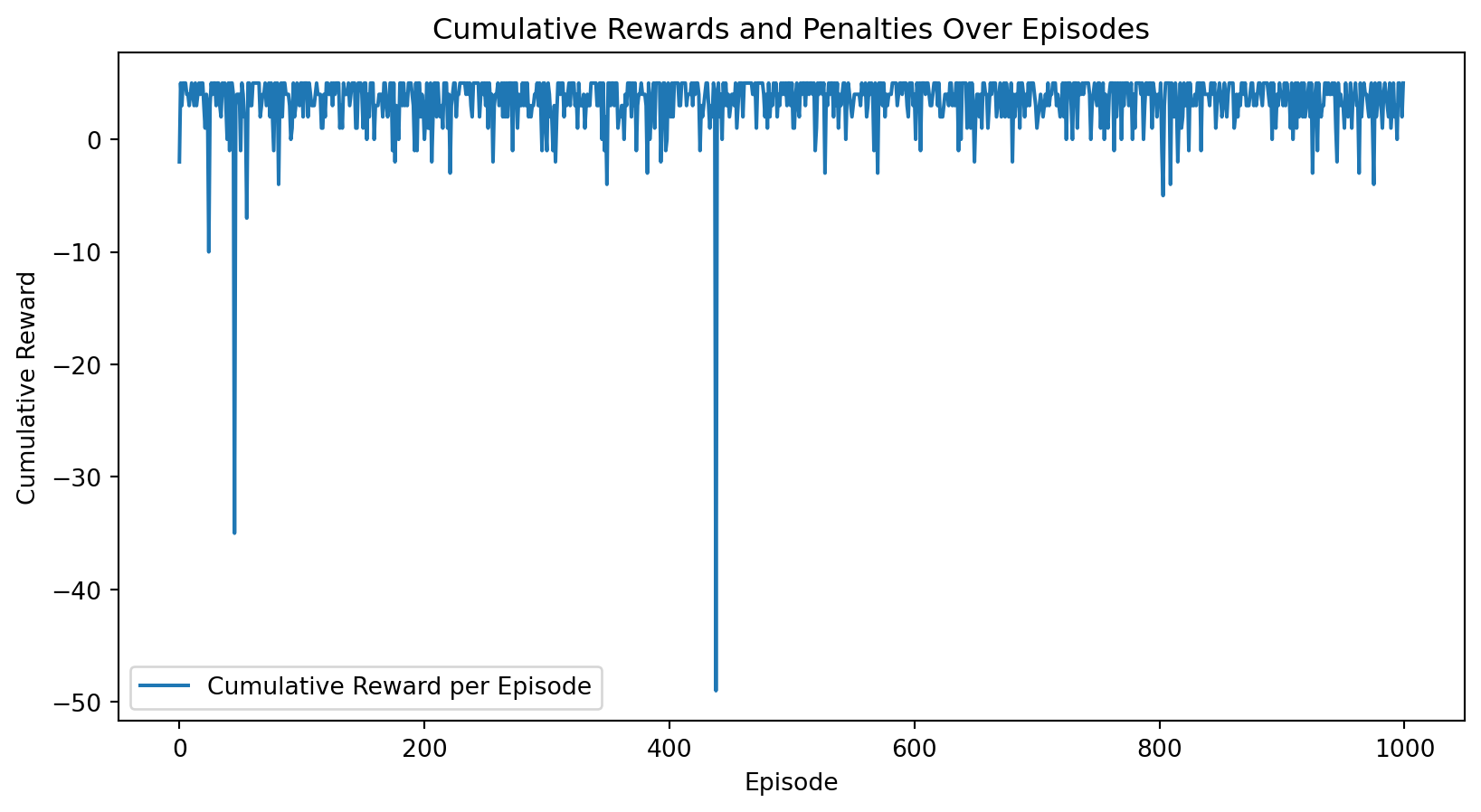
Row Data: ['Jun\n30\n1\n2\n3\n4\n5\n6', 'Jun', '30', '1', '2', '3', '4', '5', '6', 'Max Avg Min\n101 79.7 73\n79 72.7 65\n83 75.1 67\n83 75.8 68\n85 77.3 72\n90 81.0 74\n92 78.7 72', 'Max', 'Avg', 'Min', '101', '79.7', '73', '79', '72.7', '65', '83', '75.1', '67', '83', '75.8', '68', '85', '77.3', '72', '90', '81.0', '74', '92', '78.7', '72', 'Max Avg Min\n74 70.3 59\n56 53.1 46\n56 49.5 45\n58 51.5 47\n69 63.0 52\n73 70.8 69\n73 70.9 69', 'Max', 'Avg', 'Min', '74', '70.3', '59', '56', '53.1', '46', '56', '49.5', '45', '58', '51.5', '47', '69', '63.0', '52', '73', '70.8', '69', '73', '70.9', '69', 'Max Avg Min\n91 74.9 36\n65 50.9 38\n55 41.3 29\n70 43.9 28\n85 61.8 48\n87 72.1 55\n91 78.0 54', 'Max', 'Avg', 'Min', '91', '74.9', '36', '65', '50.9', '38', '55', '41.3', '29', '70', '43.9', '28', '85', '61.8', '48', '87', '72.1', '55', '91', '78.0', '54', 'Max Avg Min\n20 10.2 5\n23 14.5 8\n12 8.7 6\n18 10.3 0\n15 9.3 3\n14 7.4 0\n17 7.6 0', 'Max', 'Avg', 'Min', '20', '10.2', '5', '23', '14.5', '8', '12', '8.7', '6', '18', '10.3', '0', '15', '9.3', '3', '14', '7.4', '0', '17', '7.6', '0', 'Max Avg Min\n30.0 29.9 29.8\n30.1 30.0 29.9\n30.2 30.2 30.1\n30.2 30.1 30.0\n30.0 29.9 29.8\n29.8 29.8 29.7\n29.9 29.8 29.8', 'Max', 'Avg', 'Min', '30.0', '29.9', '29.8', '30.1', '30.0', '29.9', '30.2', '30.2', '30.1', '30.2', '30.1', '30.0', '30.0', '29.9', '29.8', '29.8', '29.8', '29.7', '29.9', '29.8', '29.8', 'Total\n0.06\n0.11\n0.00\n0.00\n0.00\n0.03\n0.11', 'Total', '0.06', '0.11', '0.00', '0.00', '0.00', '0.03', '0.11']
Row Data: ['Jun']
Row Data: ['30']
Row Data: ['1']
Row Data: ['2']
Row Data: ['3']
Row Data: ['4']
Row Data: ['5']
Row Data: ['6']
Row Data: ['Max', 'Avg', 'Min']
Row Data: ['101', '79.7', '73']
Row Data: ['79', '72.7', '65']
Row Data: ['83', '75.1', '67']
Row Data: ['83', '75.8', '68']
Row Data: ['85', '77.3', '72']
Row Data: ['90', '81.0', '74']
Row Data: ['92', '78.7', '72']
Row Data: ['Max', 'Avg', 'Min']
Row Data: ['74', '70.3', '59']
Row Data: ['56', '53.1', '46']
Row Data: ['56', '49.5', '45']
Row Data: ['58', '51.5', '47']
Row Data: ['69', '63.0', '52']
Row Data: ['73', '70.8', '69']
Row Data: ['73', '70.9', '69']
Row Data: ['Max', 'Avg', 'Min']
Row Data: ['91', '74.9', '36']
Row Data: ['65', '50.9', '38']
Row Data: ['55', '41.3', '29']
Row Data: ['70', '43.9', '28']
Row Data: ['85', '61.8', '48']
Row Data: ['87', '72.1', '55']
Row Data: ['91', '78.0', '54']
Row Data: ['Max', 'Avg', 'Min']
Row Data: ['20', '10.2', '5']
Row Data: ['23', '14.5', '8']
Row Data: ['12', '8.7', '6']
Row Data: ['18', '10.3', '0']
Row Data: ['15', '9.3', '3']
Row Data: ['14', '7.4', '0']
Row Data: ['17', '7.6', '0']
Row Data: ['Max', 'Avg', 'Min']
Row Data: ['30.0', '29.9', '29.8']
Row Data: ['30.1', '30.0', '29.9']
Row Data: ['30.2', '30.2', '30.1']
Row Data: ['30.2', '30.1', '30.0']
Row Data: ['30.0', '29.9', '29.8']
Row Data: ['29.8', '29.8', '29.7']
Row Data: ['29.9', '29.8', '29.8']
Row Data: ['Total']
Row Data: ['0.06']
Row Data: ['0.11']
Row Data: ['0.00']
Row Data: ['0.00']
Row Data: ['0.00']
Row Data: ['0.03']
Row Data: ['0.11']