Principal Component Analysis (PCA) is a dimensionality reduction technique that transforms a dataset with potentially correlated features into a set of uncorrelated components. These components are ordered by the amount of variance each one captures, allowing PCA to simplify the data structure while retaining the most informative features. This approach is widely used in unsupervised learning, particularly for data compression and noise reduction.
11.1.1 Theory
PCA works by identifying directions, or “principal components,” along which the variance of the data is maximized. Let \(X\) be a dataset with \(n\) observations and \(p\) features, represented as an \(n \times p\) matrix. The principal components are derived from the eigenvectors of the data’s covariance matrix, indicating the directions in which the data exhibits the most variation.
Standardization: To ensure that each feature contributes equally to the analysis, the features in \(X\) are often standardized to have zero mean and unit variance. This prevents features with larger scales from dominating the principal components.
Covariance Matrix: The covariance matrix \(S\) of the dataset is computed as:
\[
S = \frac{1}{n-1} X^T X.
\]
This matrix captures the pairwise covariances between features, showing how they vary together.
Eigenvalue Decomposition: PCA proceeds by calculating the eigenvalues and eigenvectors of the covariance matrix \(S\). The eigenvectors represent the principal components, and the eigenvalues measure the amount of variance each component captures.
Dimensionality Reduction: By selecting the top \(k\) eigenvectors (those with the largest eigenvalues), the data can be projected into a lower-dimensional space that retains the \(k\) most significant components:
\[
X_{\text{reduced}} = X W_k,
\]
where \(W_k\) is the matrix containing the top \(k\) eigenvectors.
11.1.2 Properties of PCA
PCA has several important properties that make it valuable for unsupervised learning:
Variance Maximization: The first principal component is the direction that maximizes variance in the data. Each subsequent component maximizes variance under the constraint of being orthogonal to previous components.
Orthogonality: Principal components are orthogonal to each other, ensuring that each captures unique information. This property transforms the data into an uncorrelated space, simplifying further analysis.
Dimensionality Reduction: By selecting only components with the largest eigenvalues, PCA enables dimensionality reduction while preserving most of the data’s variability. This is especially useful for large datasets.
Reconstruction: If all components are retained, the original data can be perfectly reconstructed. When fewer components are used, the reconstruction is approximate but retains the essential structure of the data.
Sensitivity to Scaling: PCA is sensitive to the scale of input data, so standardization is often necessary to ensure that each feature contributes equally to the analysis.
11.1.3 Interpreting PCA Results
The output of PCA provides several insights into the data:
Principal Components: Each principal component represents a linear combination of the original features. The loadings (or weights) for each feature indicate the contribution of that feature to the component. Large weights (positive or negative) suggest that the corresponding feature strongly influences the principal component.
Explained Variance: Each principal component captures a specific amount of variance in the data. The proportion of variance explained by each component helps determine how many components are needed to retain the key information in the data. For example, if the first two components explain 90% of the variance, then these two components are likely sufficient to represent the majority of the data’s structure.
Selecting the Number of Components: The cumulative explained variance plot indicates the total variance captured as more components are included. A common approach is to choose the number of components such that the cumulative variance reaches an acceptable threshold (e.g., 95%). This helps in balancing dimensionality reduction with information retention.
Interpretation of Component Scores: The transformed data points, or “scores,” in the principal component space represent each original observation as a combination of the selected principal components. Observations close together in this space have similar values on the selected components and may indicate similar patterns.
Identifying Patterns and Clusters: By visualizing the data in the reduced space, patterns and clusters may become more apparent, especially in cases where there are inherent groupings in the data. These patterns can provide insights into underlying relationships between observations.
PCA thus offers a powerful tool for both reducing data complexity and enhancing interpretability by transforming data into a simplified structure, with minimal loss of information.
11.1.4 Example: PCA on 8x8 Digit Data
The 8x8 digit dataset contains grayscale images of handwritten digits (0 through 9), with each image represented by an 8x8 grid of pixel intensities. Each pixel intensity is a feature, so each image has 64 features in total.
11.1.5 Loading and Visualizing the Data
Let’s start by loading the data and plotting some sample images to get a sense of the dataset.
# Import required librariesimport matplotlib.pyplot as pltfrom sklearn.datasets import load_digits# Load the 8x8 digit datasetdigits = load_digits()X = digits.data # feature matrix with 64 features (8x8 pixel intensities)y = digits.target # target labels (0-9 digit classes)# Display the shape of the dataprint("Feature matrix shape:", X.shape)print("Target vector shape:", y.shape)# Plot some sample images from the datasetfig, axes = plt.subplots(2, 5, figsize=(10, 4))for i, ax inenumerate(axes.flat): ax.imshow(X[i].reshape(8, 8), cmap='gray') ax.set_title(f"Digit: {y[i]}") ax.axis('off')plt.suptitle("Sample Images from 8x8 Digit Dataset", fontsize=16)plt.show()
After loading and visualizing the data, we observe the following:
Each digit is represented by a grid of 8x8 pixels, resulting in a 64-dimensional feature space.
Since each pixel represents a separate feature, the dataset has high dimensionality relative to its visual simplicity.
Given the high dimensionality of the data, we may want to address the following research questions using PCA:
Can we reduce the dimensionality of the dataset while preserving the essential structure of each digit? By reducing dimensions, we aim to simplify the data representation, which can aid in visualization and computational efficiency.
How many principal components are necessary to capture most of the variance in the data? Identifying this will help us understand how many features are truly informative in distinguishing the digits.
Are there distinct clusters in the reduced space? Visualizing the data in two or three dimensions could reveal any inherent groupings or patterns related to the different digit classes.
11.1.5.1 Performing PCA and Plotting Variance Contribution
Let’s proceed by applying PCA to the digits data and plotting the explained variance to understand how much variance each principal component captures. This will help determine the optimal number of components to retain for a good balance between dimensionality reduction and information preservation.
The primary goal here is to identify the number of components that capture most of the variance. We’ll use a cumulative explained variance plot to visualize how much total variance is captured as we include more principal components.
# Import the PCA modulefrom sklearn.decomposition import PCAimport numpy as np# Initialize PCA without specifying the number of componentspca = PCA()X_pca = pca.fit_transform(X)# Calculate the explained variance ratio for each componentexplained_variance = pca.explained_variance_ratio_cumulative_variance = np.cumsum(explained_variance)# Plot the explained variance and cumulative varianceplt.figure(figsize=(10, 5))# Plot individual explained varianceplt.subplot(1, 2, 1)plt.plot(np.arange(1, len(explained_variance) +1), explained_variance, marker='o')plt.xlabel('Principal Component')plt.ylabel('Explained Variance Ratio')plt.title('Variance Contribution of Each Component')# Plot cumulative explained varianceplt.subplot(1, 2, 2)plt.plot(np.arange(1, len(cumulative_variance) +1), cumulative_variance, marker='o')plt.xlabel('Number of Components')plt.ylabel('Cumulative Explained Variance')plt.title('Cumulative Explained Variance')plt.tight_layout()plt.show()
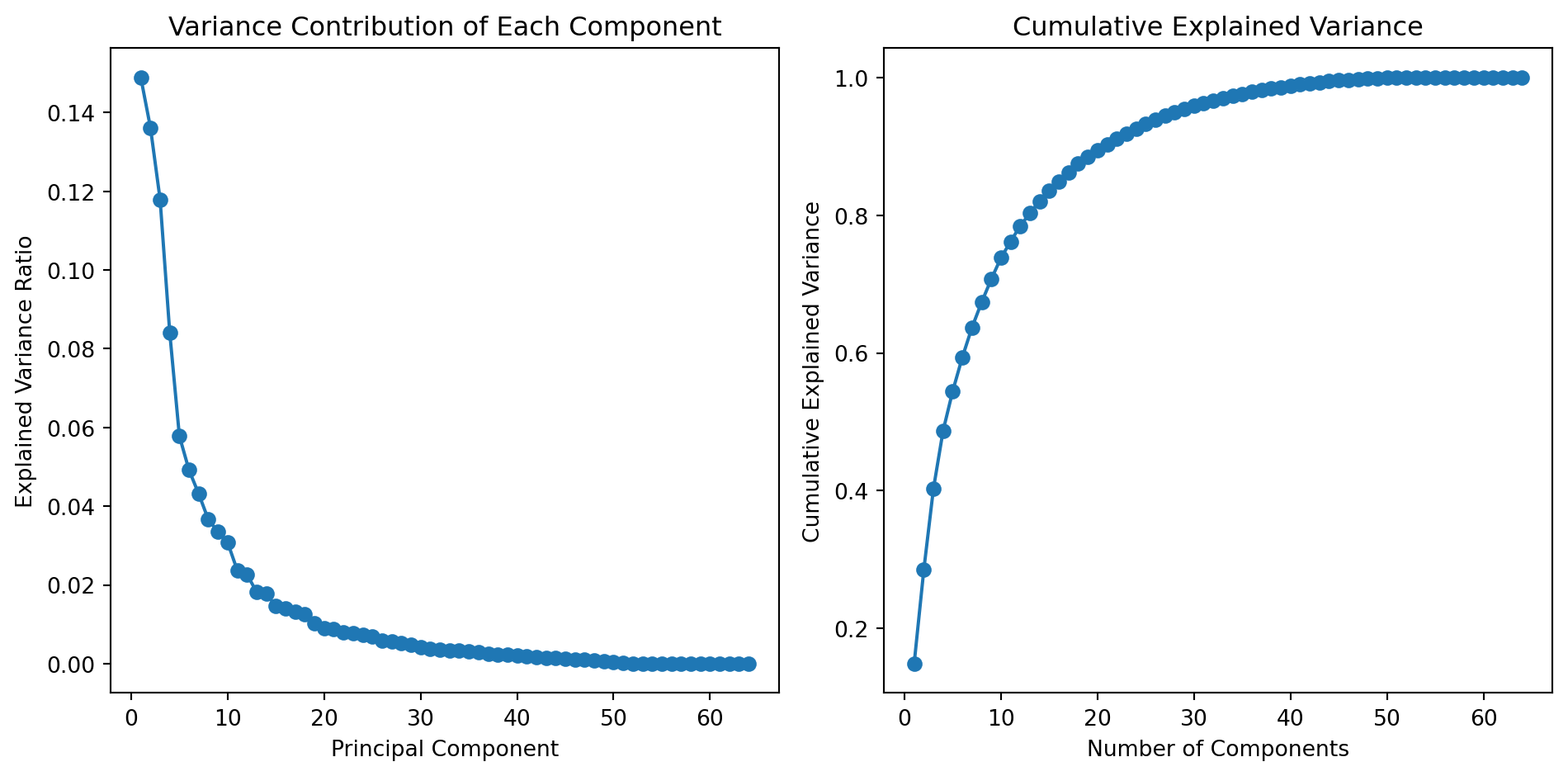
Variance Contribution of Each Component: The left plot shows the amount of variance explained by each individual component. This can help identify which components contribute significantly to capturing the variance in the data.
Cumulative Explained Variance: The right plot displays the cumulative explained variance as the number of components increases. This plot is useful for determining the number of components to retain. Generally, we look for a “knee” or “elbow” point where the cumulative variance starts to level off.
To select the number of components:
Set a Variance Threshold: A typical approach is to select enough components to capture a certain percentage of the total variance (e.g., 90% or 95%).
Elbow Method: Identify a point on the cumulative variance plot where additional components contribute minimally to the variance. This “elbow” point represents an efficient number of components.
In this example, we see that the first 10 components contain approximately 75% of the variance; around 50 components are needed to describe close to 100% of the variance.
11.1.5.2 PCA in Dimension Reduction
Let’s continue by projecting the digit data onto the first two and first three principal components, allowing us to visualize the data in a lower-dimensional space. This will help us see how well PCA captures the structure of the data and whether distinct clusters form in the reduced space.
# Apply PCA to reduce data to the first two and three componentspca_2d = PCA(n_components=2)X_pca_2d = pca_2d.fit_transform(X)pca_3d = PCA(n_components=3)X_pca_3d = pca_3d.fit_transform(X)# Plotting the 2D projectionplt.figure(figsize=(8, 6))scatter = plt.scatter(X_pca_2d[:, 0], X_pca_2d[:, 1], c=y, cmap='tab10', s=15, alpha=0.7)plt.xlabel("Principal Component 1")plt.ylabel("Principal Component 2")plt.title("2D PCA Projection of Digit Data")plt.colorbar(scatter, label='Digit Label')plt.show()# Plotting the 3D projectionfrom mpl_toolkits.mplot3d import Axes3Dfig = plt.figure(figsize=(10, 7))ax = fig.add_subplot(111, projection='3d')scatter = ax.scatter(X_pca_3d[:, 0], X_pca_3d[:, 1], X_pca_3d[:, 2], c=y, cmap='tab10', s=15, alpha=0.7)ax.set_xlabel("Principal Component 1")ax.set_ylabel("Principal Component 2")ax.set_zlabel("Principal Component 3")ax.set_title("3D PCA Projection of Digit Data")fig.colorbar(scatter, ax=ax, label='Digit Label')plt.show()
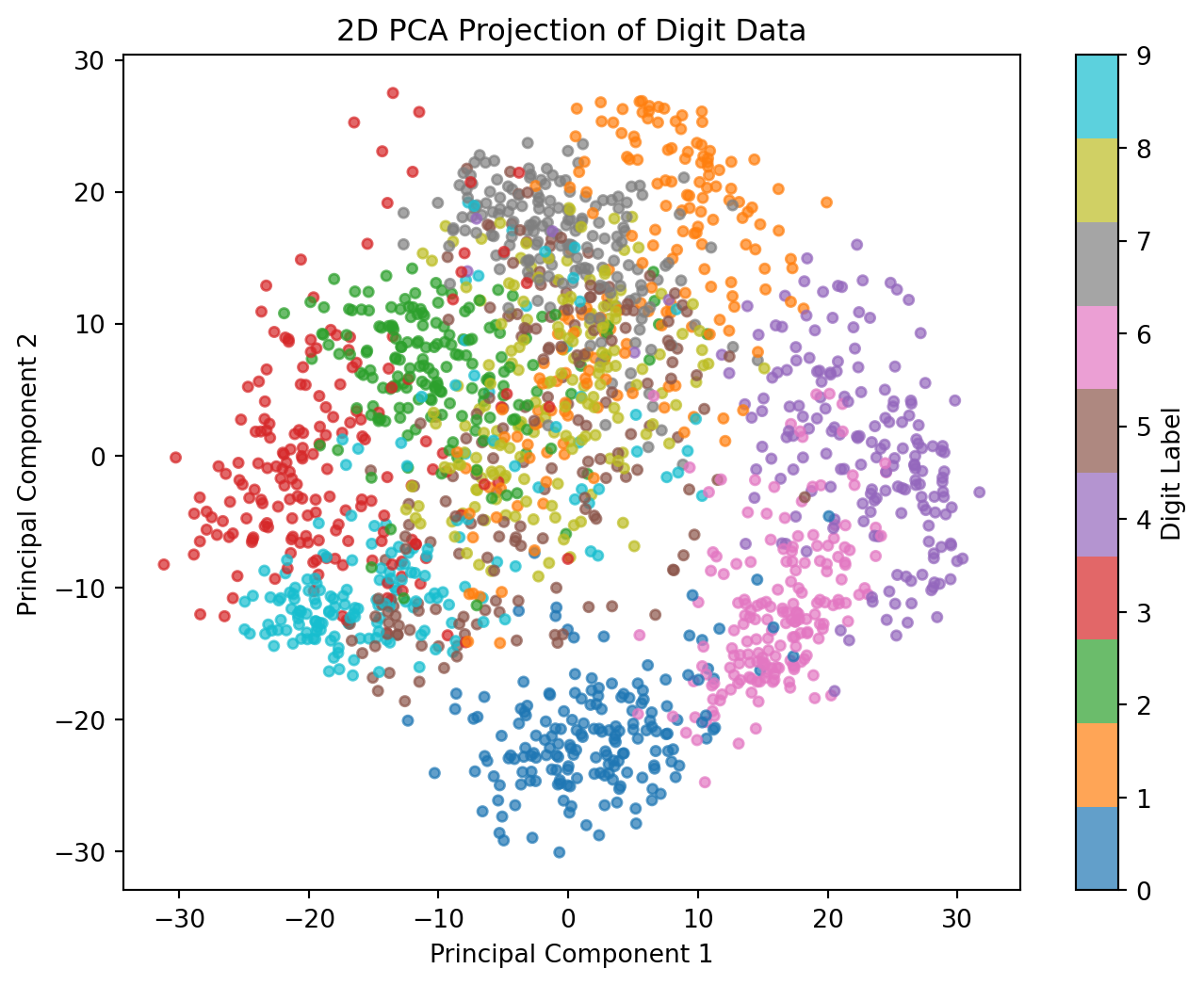
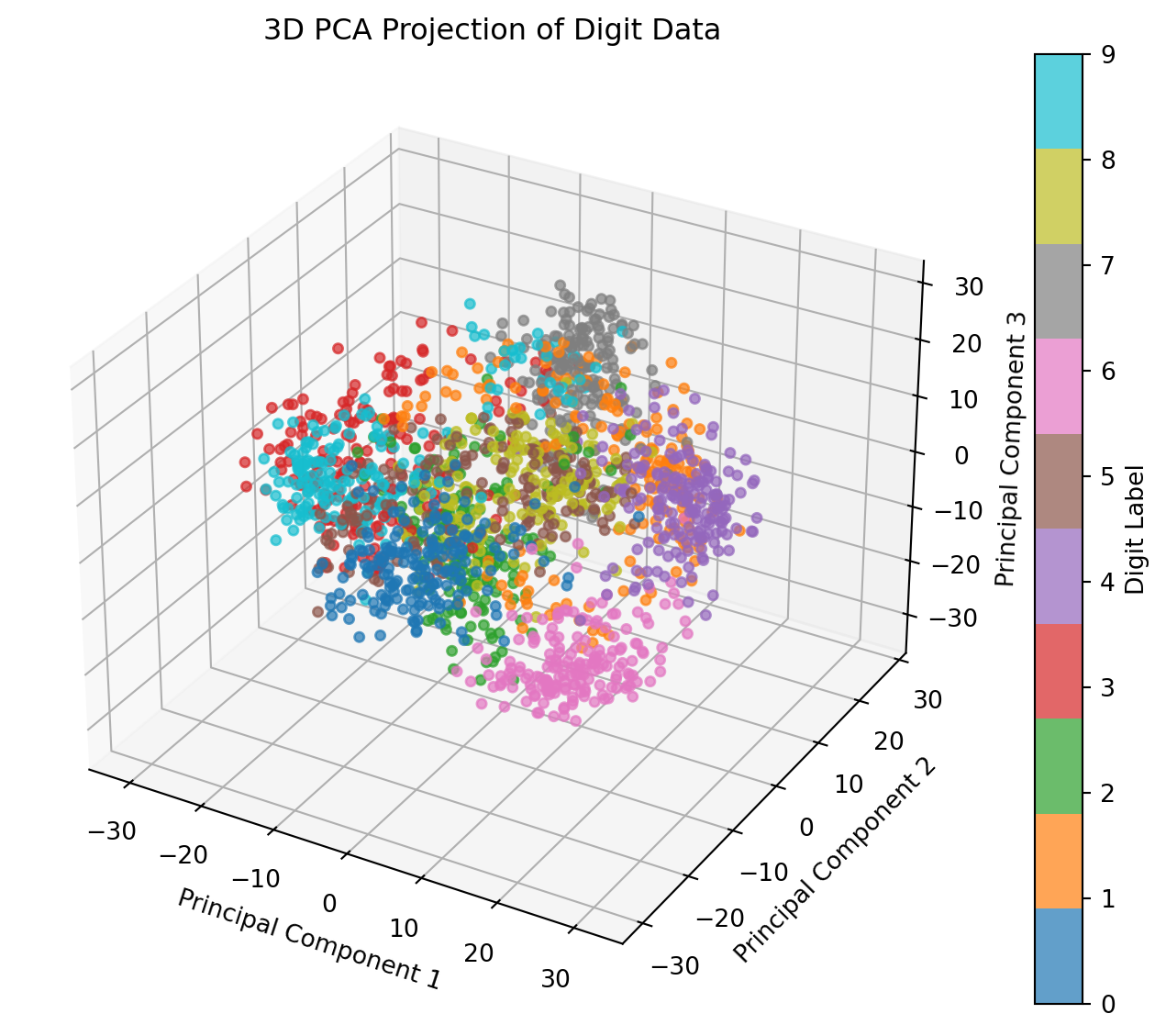
This 3D projection of the MNIST digit data shows each image’s position in the space defined by the first three principal components. Here are some key observations:
Cluster Formation: Distinct clusters of points represent different digits. Digits with similar shapes, such as “1” and “7” (both often vertical), may appear closer to each other in this reduced space. This clustering suggests that PCA effectively captures structural features, even when reducing dimensions.
Effectiveness of Dimensionality Reduction: Despite reducing from 64 dimensions to only three, PCA retains essential variance, allowing for distinction between different digits. This demonstrates PCA’s utility in data compression, providing a simplified representation without losing significant information.
Exploring Further Dimensions: Additional components could capture more variance, if required. However, the first three components often capture most of the meaningful variance, balancing dimensionality reduction with information retention.
This PCA projection shows that the MNIST digit data has underlying patterns well-represented by the first few components. These findings highlight PCA’s usefulness in compressing high-dimensional data while preserving its structure, making it a valuable tool for visualization, noise reduction, and as a pre-processing step in machine learning tasks.
11.1.5.3 PCA in Noise Filtering
To demonstrate PCA’s use in noise filtering, we’ll follow these steps:
Add Random Noise: Add random noise to the original digit images.
Fit PCA to Noisy Data: Apply PCA to the noisy data, selecting enough components to retain 50% of the variance.
Reconstruct the Digits: Use PCA’s inverse transform to reconstruct the digits from the reduced components, effectively filtering out the noise.
Display the Results: Show a side-by-side comparison of the original, perturbed, and reconstructed images for visual assessment.
def plot_digits(datasets, titles):""" Plots a 2x5 grid of images for each dataset in datasets, using a compact and uniform layout. Parameters: - datasets: list of 2D numpy arrays, each array with shape (n_samples, 64), representing different versions of the digit data (e.g., original, noisy, reconstructed). - titles: list of strings, titles for each dataset (e.g., ["Original", "Noisy", "Reconstructed"]). """ fig, axes = plt.subplots(len(datasets) *2, 5, figsize=(5, 6), subplot_kw={'xticks':[], 'yticks':[]}, gridspec_kw=dict(hspace=0.1, wspace=0.1))for row, (data, title) inenumerate(zip(datasets, titles)):for i, ax inenumerate(axes[row *2: row *2+2].flat): ax.imshow(data[i].reshape(8, 8), cmap='binary', interpolation='nearest', clim=(0, 16)) axes[row *2, 0].set_ylabel(title, rotation=0, labelpad=30, fontsize=12, ha='right') plt.suptitle("PCA Noise Filtering: Original, Noisy, and Reconstructed Digits", fontsize=16)# plt.tight_layout() plt.show()# Applying the function to the original, noisy, and reconstructed datasets# Load the 8x8 digit datasetdigits = load_digits()X = digits.data # Original digit data# Add random noise to the datanp.random.seed(0)noise = np.random.normal(0, 4, X.shape)X_noisy = X + noise# Fit PCA to retain 50% of the variancepca_50 = PCA(0.50)X_pca_50 = pca_50.fit_transform(X_noisy)X_reconstructed_50 = pca_50.inverse_transform(X_pca_50)# Plot the original, noisy, and reconstructed digits using the functionplot_digits([X, X_noisy, X_reconstructed_50], ["Original", "Noisy", "Reconstructed"])
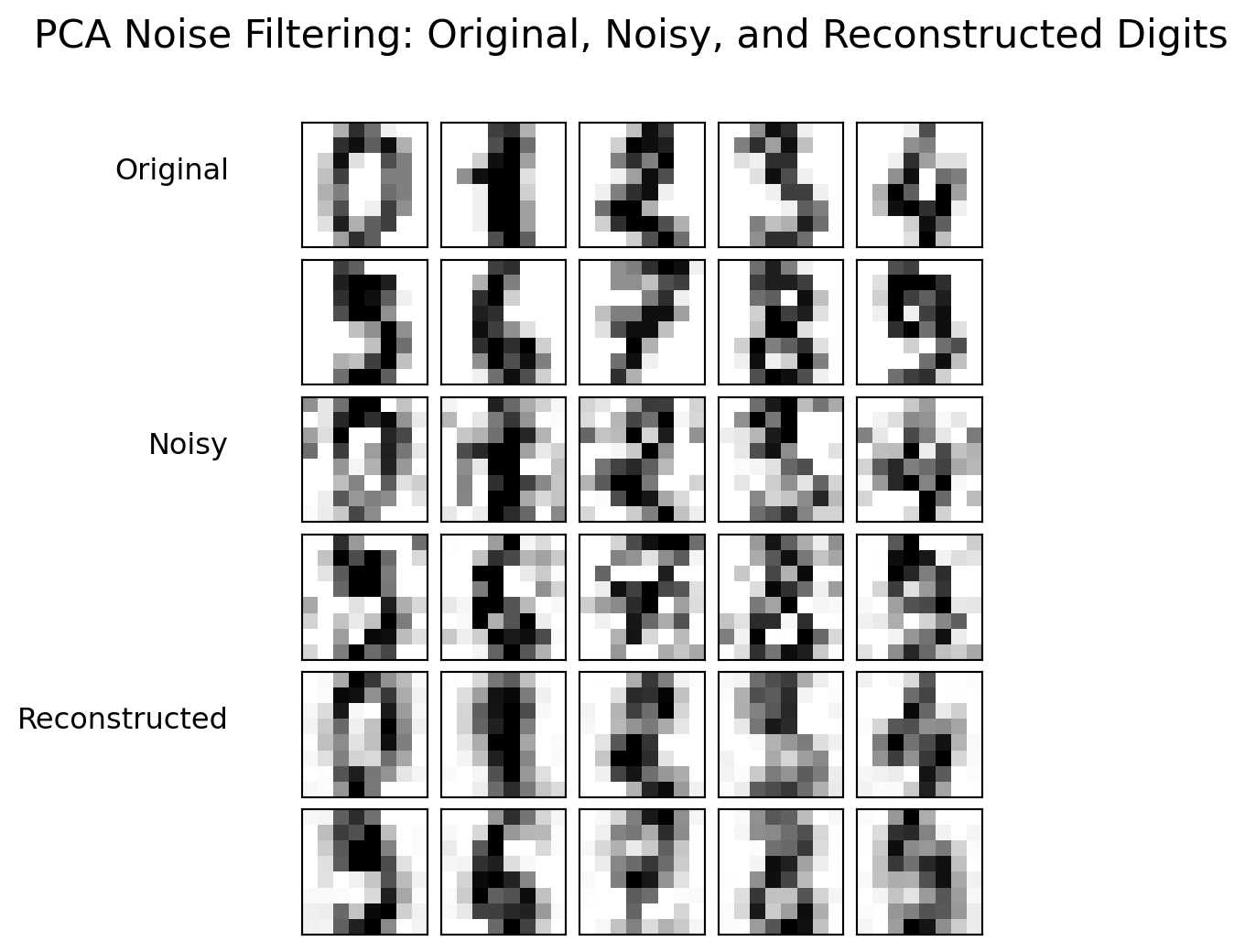
This visualization demonstrates the noise filtering effect of PCA:
Original vs. Noisy Images: The second row shows the effect of added random noise, making the digits less recognizable.
Reconstructed Images: In the third row, PCA has filtered out much of the random noise, reconstructing cleaner versions of the digits while preserving important structural features. This illustrates PCA’s effectiveness in noise reduction by retaining only the principal components that capture meaningful variance.