import nltk12 Advanced Topics
12.1 Text Analysis with nltk (by Shivaram Karandikar)
12.1.1 Introduction
nltk, or Natural Language Toolkit, is a Python package which provides a set of tools for text analysis. nltk is used in Natural Language Processing (NLP), a field of computer science which focuses on the interaction between computers and human languages. nltk is a very powerful tool for text analysis, and is used by many researchers and data scientists. In this tutorial, we will learn how to use nltk to analyze text.
12.1.2 Getting Started
First, we must install nltk using pip.
python -m pip install nltk
Necessary datasets/models are needed for specific functions to work. We can download a popular subset with
python -m nltk.downloader popular
12.1.3 Tokenizing
To analyze text, it needs to be broken down into smaller pieces. This is called tokenization. nltk offers two ways to tokenize text: sentence tokenization and word tokenization.
To demonstrate this, we will use the following text, a passage from the 1951 science fiction novel Foundation by Isaac Asimov.
fd_string = """The sum of human knowing is beyond any one man; any thousand men. With the destruction of our social fabric, science will be broken into a million pieces. Individuals will know much of exceedingly tiny facets of what there is to know. They will be helpless and useless by themselves. The bits of lore, meaningless, will not be passed on. They will be lost through the generations. But, if we now prepare a giant summary of all knowledge, it will never be lost. Coming generations will build on it, and will not have to rediscover it for themselves. One millennium will do the work of thirty thousand."""12.1.3.1 Sentence Tokenization
from nltk import sent_tokenize, word_tokenize
nltk.download("popular") # only needs to download once
fd_sent = sent_tokenize(fd_string)
print(fd_sent)[nltk_data] Downloading collection 'popular'
[nltk_data] |
[nltk_data] | Downloading package cmudict to
[nltk_data] | /Users/junyan/nltk_data...
[nltk_data] | Package cmudict is already up-to-date!
[nltk_data] | Downloading package gazetteers to
[nltk_data] | /Users/junyan/nltk_data...
[nltk_data] | Package gazetteers is already up-to-date!
[nltk_data] | Downloading package genesis to
[nltk_data] | /Users/junyan/nltk_data...
[nltk_data] | Package genesis is already up-to-date!
[nltk_data] | Downloading package gutenberg to
[nltk_data] | /Users/junyan/nltk_data...
[nltk_data] | Package gutenberg is already up-to-date!
[nltk_data] | Downloading package inaugural to
[nltk_data] | /Users/junyan/nltk_data...
[nltk_data] | Package inaugural is already up-to-date!
[nltk_data] | Downloading package movie_reviews to
[nltk_data] | /Users/junyan/nltk_data...
[nltk_data] | Package movie_reviews is already up-to-date!
[nltk_data] | Downloading package names to
[nltk_data] | /Users/junyan/nltk_data...
[nltk_data] | Package names is already up-to-date!
[nltk_data] | Downloading package shakespeare to
[nltk_data] | /Users/junyan/nltk_data...
[nltk_data] | Package shakespeare is already up-to-date!
[nltk_data] | Downloading package stopwords to
[nltk_data] | /Users/junyan/nltk_data...
[nltk_data] | Package stopwords is already up-to-date!
[nltk_data] | Downloading package treebank to
[nltk_data] | /Users/junyan/nltk_data...[nltk_data] | Package treebank is already up-to-date!
[nltk_data] | Downloading package twitter_samples to
[nltk_data] | /Users/junyan/nltk_data...
[nltk_data] | Package twitter_samples is already up-to-date!
[nltk_data] | Downloading package omw to /Users/junyan/nltk_data...
[nltk_data] | Package omw is already up-to-date!
[nltk_data] | Downloading package omw-1.4 to
[nltk_data] | /Users/junyan/nltk_data...
[nltk_data] | Package omw-1.4 is already up-to-date!
[nltk_data] | Downloading package wordnet to
[nltk_data] | /Users/junyan/nltk_data...
[nltk_data] | Package wordnet is already up-to-date!
[nltk_data] | Downloading package wordnet2021 to
[nltk_data] | /Users/junyan/nltk_data...[nltk_data] | Package wordnet2021 is already up-to-date!
[nltk_data] | Downloading package wordnet31 to
[nltk_data] | /Users/junyan/nltk_data...
[nltk_data] | Package wordnet31 is already up-to-date!
[nltk_data] | Downloading package wordnet_ic to
[nltk_data] | /Users/junyan/nltk_data...
[nltk_data] | Package wordnet_ic is already up-to-date!
[nltk_data] | Downloading package words to
[nltk_data] | /Users/junyan/nltk_data...
[nltk_data] | Package words is already up-to-date!
[nltk_data] | Downloading package maxent_ne_chunker to
[nltk_data] | /Users/junyan/nltk_data...
[nltk_data] | Package maxent_ne_chunker is already up-to-date!
[nltk_data] | Downloading package punkt to
[nltk_data] | /Users/junyan/nltk_data...
[nltk_data] | Package punkt is already up-to-date!
[nltk_data] | Downloading package snowball_data to
[nltk_data] | /Users/junyan/nltk_data...
[nltk_data] | Package snowball_data is already up-to-date!
[nltk_data] | Downloading package averaged_perceptron_tagger to
[nltk_data] | /Users/junyan/nltk_data...['The sum of human knowing is beyond any one man; any thousand men.', 'With the destruction of our social fabric, science will be broken into a million pieces.', 'Individuals will know much of exceedingly tiny facets of what there is to know.', 'They will be helpless and useless by themselves.', 'The bits of lore, meaningless, will not be passed on.', 'They will be lost through the generations.', 'But, if we now prepare a giant summary of all knowledge, it will never be lost.', 'Coming generations will build on it, and will not have to rediscover it for themselves.', 'One millennium will do the work of thirty thousand.'][nltk_data] | Package averaged_perceptron_tagger is already up-
[nltk_data] | to-date!
[nltk_data] |
[nltk_data] Done downloading collection popular12.1.3.2 Word Tokenization
fd_word = word_tokenize(fd_string)
print(fd_word)['The', 'sum', 'of', 'human', 'knowing', 'is', 'beyond', 'any', 'one', 'man', ';', 'any', 'thousand', 'men', '.', 'With', 'the', 'destruction', 'of', 'our', 'social', 'fabric', ',', 'science', 'will', 'be', 'broken', 'into', 'a', 'million', 'pieces', '.', 'Individuals', 'will', 'know', 'much', 'of', 'exceedingly', 'tiny', 'facets', 'of', 'what', 'there', 'is', 'to', 'know', '.', 'They', 'will', 'be', 'helpless', 'and', 'useless', 'by', 'themselves', '.', 'The', 'bits', 'of', 'lore', ',', 'meaningless', ',', 'will', 'not', 'be', 'passed', 'on', '.', 'They', 'will', 'be', 'lost', 'through', 'the', 'generations', '.', 'But', ',', 'if', 'we', 'now', 'prepare', 'a', 'giant', 'summary', 'of', 'all', 'knowledge', ',', 'it', 'will', 'never', 'be', 'lost', '.', 'Coming', 'generations', 'will', 'build', 'on', 'it', ',', 'and', 'will', 'not', 'have', 'to', 'rediscover', 'it', 'for', 'themselves', '.', 'One', 'millennium', 'will', 'do', 'the', 'work', 'of', 'thirty', 'thousand', '.']Both the sentence tokenization and word tokenization functions return a list of strings. We can use these lists to perform further analysis.
12.1.4 Removing Stopwords
The output of the word tokenization gave us a list of words. However, some of these words are not useful for our analysis. These words are called stopwords. nltk provides a list of stopwords for several languages. We can use this list to remove stopwords from our text.
from nltk.corpus import stopwords
stop_words = set(stopwords.words("english"))
print(stop_words){"you'd", 'being', 'at', 'after', 'their', 's', 'all', 'couldn', 'here', 'same', 'she', "weren't", 'some', 'too', 'i', 'can', 'of', 'you', 'than', 'd', "you'll", 'the', 't', 'above', "should've", 'has', 'ours', 'where', 'from', 'wouldn', 'is', 'hasn', 'am', 'its', 'ain', 'our', 'should', 'in', 'your', 'those', 'had', 'if', 'weren', 'into', 'have', "doesn't", "isn't", 'aren', 'me', 'whom', 'how', 'll', 'themselves', 'and', 'myself', 'over', 'once', 'did', 'then', 'so', 'we', 'mustn', 'won', 'both', 'between', 'now', 'with', "she's", 'shan', 'about', 'his', 'itself', 'or', 'up', "wouldn't", "couldn't", "aren't", 'having', 'these', 'to', 'each', 'own', 'were', 'until', 'been', 'are', 'yours', 'off', 'this', 'such', 'don', 've', 'they', 'was', "shan't", 'hadn', 'an', "hadn't", 'under', 'when', 'haven', "mustn't", 'who', "didn't", "wasn't", 'ma', 'just', 'mightn', 'very', 'be', 'no', 'more', 'other', 'out', "don't", "won't", 'm', 'ourselves', "haven't", 'by', 'herself', 'o', 'a', 'most', 'hers', 'few', 'during', "you're", "you've", 'further', 'why', "hasn't", 'as', "needn't", "that'll", "mightn't", 'nor', "it's", 'only', 'doesn', 'that', 'through', 'theirs', 'isn', 're', 'her', 'my', 'them', 'what', 'which', 'y', 'before', 'there', 'didn', 'not', 'while', 'down', 'against', 'below', 'himself', 'does', 'because', 'again', 'needn', 'shouldn', 'yourselves', 'wasn', 'will', 'do', 'but', 'doing', 'on', 'he', 'it', 'any', 'him', "shouldn't", 'for', 'yourself'}fd_filtered = [w for w in fd_word if w.casefold() not in stop_words]
print(fd_filtered)['sum', 'human', 'knowing', 'beyond', 'one', 'man', ';', 'thousand', 'men', '.', 'destruction', 'social', 'fabric', ',', 'science', 'broken', 'million', 'pieces', '.', 'Individuals', 'know', 'much', 'exceedingly', 'tiny', 'facets', 'know', '.', 'helpless', 'useless', '.', 'bits', 'lore', ',', 'meaningless', ',', 'passed', '.', 'lost', 'generations', '.', ',', 'prepare', 'giant', 'summary', 'knowledge', ',', 'never', 'lost', '.', 'Coming', 'generations', 'build', ',', 'rediscover', '.', 'One', 'millennium', 'work', 'thirty', 'thousand', '.']The resulting list is significantly shorter. There are some words that nltk considers stopwords that we may want to keep, depending on the objective of our analysis. Reducing the size of our data can help us to reduce the time it takes to perform our analysis. However, removing too many words can reduce the accuracy, which is especially important when we are trying to perform sentiment analysis.
12.1.5 Stemming
Stemming is a method which allows us to reduce the number of variants of a word. For example, the words connecting, connected, and connection are all variants of the same word connect. nltk includes a few different stemmers based on different algorithms. We will use the Snowball stemmer, an improved version of the 1979 Porter stemmer.
from nltk.stem.snowball import SnowballStemmer
snow_stem = SnowballStemmer(language='english')
fd_stem = [snow_stem.stem(w) for w in fd_word]
print(fd_stem)['the', 'sum', 'of', 'human', 'know', 'is', 'beyond', 'ani', 'one', 'man', ';', 'ani', 'thousand', 'men', '.', 'with', 'the', 'destruct', 'of', 'our', 'social', 'fabric', ',', 'scienc', 'will', 'be', 'broken', 'into', 'a', 'million', 'piec', '.', 'individu', 'will', 'know', 'much', 'of', 'exceed', 'tini', 'facet', 'of', 'what', 'there', 'is', 'to', 'know', '.', 'they', 'will', 'be', 'helpless', 'and', 'useless', 'by', 'themselv', '.', 'the', 'bit', 'of', 'lore', ',', 'meaningless', ',', 'will', 'not', 'be', 'pass', 'on', '.', 'they', 'will', 'be', 'lost', 'through', 'the', 'generat', '.', 'but', ',', 'if', 'we', 'now', 'prepar', 'a', 'giant', 'summari', 'of', 'all', 'knowledg', ',', 'it', 'will', 'never', 'be', 'lost', '.', 'come', 'generat', 'will', 'build', 'on', 'it', ',', 'and', 'will', 'not', 'have', 'to', 'rediscov', 'it', 'for', 'themselv', '.', 'one', 'millennium', 'will', 'do', 'the', 'work', 'of', 'thirti', 'thousand', '.']Stemming algorithms are susceptible to errors. Related words that should share a stem may not, which is known as understemming, which is a false negative. Unrelated words that should not share a stem may, which is known as overstemming, which is a false positive.
12.1.6 POS Tagging
nltk also enables us to label the parts of speech of each word in a text. This is known as part-of-speech (POS) tagging. nltk uses the Penn Treebank tagset, which is a set of tags that are used to label words in a text. The tags are as follows:
nltk.help.upenn_tagset()$: dollar
$ -$ --$ A$ C$ HK$ M$ NZ$ S$ U.S.$ US$
'': closing quotation mark
' ''
(: opening parenthesis
( [ {
): closing parenthesis
) ] }
,: comma
,
--: dash
--
.: sentence terminator
. ! ?
:: colon or ellipsis
: ; ...
CC: conjunction, coordinating
& 'n and both but either et for less minus neither nor or plus so
therefore times v. versus vs. whether yet
CD: numeral, cardinal
mid-1890 nine-thirty forty-two one-tenth ten million 0.5 one forty-
seven 1987 twenty '79 zero two 78-degrees eighty-four IX '60s .025
fifteen 271,124 dozen quintillion DM2,000 ...
DT: determiner
all an another any both del each either every half la many much nary
neither no some such that the them these this those
EX: existential there
there
FW: foreign word
gemeinschaft hund ich jeux habeas Haementeria Herr K'ang-si vous
lutihaw alai je jour objets salutaris fille quibusdam pas trop Monte
terram fiche oui corporis ...
IN: preposition or conjunction, subordinating
astride among uppon whether out inside pro despite on by throughout
below within for towards near behind atop around if like until below
next into if beside ...
JJ: adjective or numeral, ordinal
third ill-mannered pre-war regrettable oiled calamitous first separable
ectoplasmic battery-powered participatory fourth still-to-be-named
multilingual multi-disciplinary ...
JJR: adjective, comparative
bleaker braver breezier briefer brighter brisker broader bumper busier
calmer cheaper choosier cleaner clearer closer colder commoner costlier
cozier creamier crunchier cuter ...
JJS: adjective, superlative
calmest cheapest choicest classiest cleanest clearest closest commonest
corniest costliest crassest creepiest crudest cutest darkest deadliest
dearest deepest densest dinkiest ...
LS: list item marker
A A. B B. C C. D E F First G H I J K One SP-44001 SP-44002 SP-44005
SP-44007 Second Third Three Two * a b c d first five four one six three
two
MD: modal auxiliary
can cannot could couldn't dare may might must need ought shall should
shouldn't will would
NN: noun, common, singular or mass
common-carrier cabbage knuckle-duster Casino afghan shed thermostat
investment slide humour falloff slick wind hyena override subhumanity
machinist ...
NNP: noun, proper, singular
Motown Venneboerger Czestochwa Ranzer Conchita Trumplane Christos
Oceanside Escobar Kreisler Sawyer Cougar Yvette Ervin ODI Darryl CTCA
Shannon A.K.C. Meltex Liverpool ...
NNPS: noun, proper, plural
Americans Americas Amharas Amityvilles Amusements Anarcho-Syndicalists
Andalusians Andes Andruses Angels Animals Anthony Antilles Antiques
Apache Apaches Apocrypha ...
NNS: noun, common, plural
undergraduates scotches bric-a-brac products bodyguards facets coasts
divestitures storehouses designs clubs fragrances averages
subjectivists apprehensions muses factory-jobs ...
PDT: pre-determiner
all both half many quite such sure this
POS: genitive marker
' 's
PRP: pronoun, personal
hers herself him himself hisself it itself me myself one oneself ours
ourselves ownself self she thee theirs them themselves they thou thy us
PRP$: pronoun, possessive
her his mine my our ours their thy your
RB: adverb
occasionally unabatingly maddeningly adventurously professedly
stirringly prominently technologically magisterially predominately
swiftly fiscally pitilessly ...
RBR: adverb, comparative
further gloomier grander graver greater grimmer harder harsher
healthier heavier higher however larger later leaner lengthier less-
perfectly lesser lonelier longer louder lower more ...
RBS: adverb, superlative
best biggest bluntest earliest farthest first furthest hardest
heartiest highest largest least less most nearest second tightest worst
RP: particle
aboard about across along apart around aside at away back before behind
by crop down ever fast for forth from go high i.e. in into just later
low more off on open out over per pie raising start teeth that through
under unto up up-pp upon whole with you
SYM: symbol
% & ' '' ''. ) ). * + ,. < = > @ A[fj] U.S U.S.S.R * ** ***
TO: "to" as preposition or infinitive marker
to
UH: interjection
Goodbye Goody Gosh Wow Jeepers Jee-sus Hubba Hey Kee-reist Oops amen
huh howdy uh dammit whammo shucks heck anyways whodunnit honey golly
man baby diddle hush sonuvabitch ...
VB: verb, base form
ask assemble assess assign assume atone attention avoid bake balkanize
bank begin behold believe bend benefit bevel beware bless boil bomb
boost brace break bring broil brush build ...
VBD: verb, past tense
dipped pleaded swiped regummed soaked tidied convened halted registered
cushioned exacted snubbed strode aimed adopted belied figgered
speculated wore appreciated contemplated ...
VBG: verb, present participle or gerund
telegraphing stirring focusing angering judging stalling lactating
hankerin' alleging veering capping approaching traveling besieging
encrypting interrupting erasing wincing ...
VBN: verb, past participle
multihulled dilapidated aerosolized chaired languished panelized used
experimented flourished imitated reunifed factored condensed sheared
unsettled primed dubbed desired ...
VBP: verb, present tense, not 3rd person singular
predominate wrap resort sue twist spill cure lengthen brush terminate
appear tend stray glisten obtain comprise detest tease attract
emphasize mold postpone sever return wag ...
VBZ: verb, present tense, 3rd person singular
bases reconstructs marks mixes displeases seals carps weaves snatches
slumps stretches authorizes smolders pictures emerges stockpiles
seduces fizzes uses bolsters slaps speaks pleads ...
WDT: WH-determiner
that what whatever which whichever
WP: WH-pronoun
that what whatever whatsoever which who whom whosoever
WP$: WH-pronoun, possessive
whose
WRB: Wh-adverb
how however whence whenever where whereby whereever wherein whereof why
``: opening quotation mark
` ``We can use the function nltk.pos_tag() on our list of tokenized words. This will return a list of tuples, where each tuple contains a word and its corresponding tag.
fd_tag = nltk.pos_tag(fd_word)
print(fd_tag)[('The', 'DT'), ('sum', 'NN'), ('of', 'IN'), ('human', 'JJ'), ('knowing', 'NN'), ('is', 'VBZ'), ('beyond', 'IN'), ('any', 'DT'), ('one', 'CD'), ('man', 'NN'), (';', ':'), ('any', 'DT'), ('thousand', 'CD'), ('men', 'NNS'), ('.', '.'), ('With', 'IN'), ('the', 'DT'), ('destruction', 'NN'), ('of', 'IN'), ('our', 'PRP$'), ('social', 'JJ'), ('fabric', 'NN'), (',', ','), ('science', 'NN'), ('will', 'MD'), ('be', 'VB'), ('broken', 'VBN'), ('into', 'IN'), ('a', 'DT'), ('million', 'CD'), ('pieces', 'NNS'), ('.', '.'), ('Individuals', 'NNS'), ('will', 'MD'), ('know', 'VB'), ('much', 'RB'), ('of', 'IN'), ('exceedingly', 'RB'), ('tiny', 'JJ'), ('facets', 'NNS'), ('of', 'IN'), ('what', 'WP'), ('there', 'EX'), ('is', 'VBZ'), ('to', 'TO'), ('know', 'VB'), ('.', '.'), ('They', 'PRP'), ('will', 'MD'), ('be', 'VB'), ('helpless', 'JJ'), ('and', 'CC'), ('useless', 'JJ'), ('by', 'IN'), ('themselves', 'PRP'), ('.', '.'), ('The', 'DT'), ('bits', 'NNS'), ('of', 'IN'), ('lore', 'NN'), (',', ','), ('meaningless', 'NN'), (',', ','), ('will', 'MD'), ('not', 'RB'), ('be', 'VB'), ('passed', 'VBN'), ('on', 'IN'), ('.', '.'), ('They', 'PRP'), ('will', 'MD'), ('be', 'VB'), ('lost', 'VBN'), ('through', 'IN'), ('the', 'DT'), ('generations', 'NNS'), ('.', '.'), ('But', 'CC'), (',', ','), ('if', 'IN'), ('we', 'PRP'), ('now', 'RB'), ('prepare', 'VBP'), ('a', 'DT'), ('giant', 'JJ'), ('summary', 'NN'), ('of', 'IN'), ('all', 'DT'), ('knowledge', 'NN'), (',', ','), ('it', 'PRP'), ('will', 'MD'), ('never', 'RB'), ('be', 'VB'), ('lost', 'VBN'), ('.', '.'), ('Coming', 'VBG'), ('generations', 'NNS'), ('will', 'MD'), ('build', 'VB'), ('on', 'IN'), ('it', 'PRP'), (',', ','), ('and', 'CC'), ('will', 'MD'), ('not', 'RB'), ('have', 'VB'), ('to', 'TO'), ('rediscover', 'VB'), ('it', 'PRP'), ('for', 'IN'), ('themselves', 'PRP'), ('.', '.'), ('One', 'CD'), ('millennium', 'NN'), ('will', 'MD'), ('do', 'VB'), ('the', 'DT'), ('work', 'NN'), ('of', 'IN'), ('thirty', 'JJ'), ('thousand', 'NN'), ('.', '.')]The tokenized words from the quote should be easy to tag correctly. The function may encounter difficulty with less conventional words (e.g. Old English), but it will attempt to tag based on context.
12.1.7 Lemmatizing
Lemmatizing is similar to stemming, but it is more accurate. Lemmatizing is a process which reduces words to their lemma, which is the base form of a word.nltk includes a lemmatizer based on the WordNet database. We can demonstrate this using a quote from the 1868 novel Little Women by Louisa May Alcott.
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
quote = "The dim, dusty room, with the busts staring down from the tall book-cases, the cosy chairs, the globes, and, best of all, the wilderness of books, in which she could wander where she liked, made the library a region of bliss to her."
quote_token = word_tokenize(quote)
quote_lemma = [lemmatizer.lemmatize(w) for w in quote_token]
print(quote_lemma)['The', 'dim', ',', 'dusty', 'room', ',', 'with', 'the', 'bust', 'staring', 'down', 'from', 'the', 'tall', 'book-cases', ',', 'the', 'cosy', 'chair', ',', 'the', 'globe', ',', 'and', ',', 'best', 'of', 'all', ',', 'the', 'wilderness', 'of', 'book', ',', 'in', 'which', 'she', 'could', 'wander', 'where', 'she', 'liked', ',', 'made', 'the', 'library', 'a', 'region', 'of', 'bliss', 'to', 'her', '.']12.1.8 Chunking/Chinking
While tokenizing allows us to distinguish individual words and sentences within a larger body of text, Chunking allows us to identify phrases based on grammar we specify.
#nltk.download("averaged_perceptron_tagger")
quote_tag = nltk.pos_tag(quote_token)We can then name grammar rules to apply to the text. These use regular expressions, which are listed below:
| Operator | Behavior |
| . | Wildcard, matches any character |
| ^abc | Matches some pattern abc at the start of a string |
| abc$ | Matches some pattern abc at the end of a string |
| [abc] | Matches one of a set of characters |
| [A-Z0-9] | Matches one of a range of characters |
| ed|ing|s | Matches one of the specified strings (disjunction) |
| * | Zero or more of previous item, e.g. a*, [a-z]* (also known as Kleene Closure) |
| + | One or more of previous item, e.g. a+, [a-z]+ |
| ? | Zero or one of the previous item (i.e. optional), e.g. a?, [a-z]? |
| {n} | Exactly n repeats where n is a non-negative integer |
| {n,} | At least n repeats |
| {,n} | No more than n repeats |
| {m,n} | At least m and no more than n repeats |
| a(b|c)+ | Parentheses that indicate the scope of the operators |
import re
import regexgrammar = r"""
NP: {<DT|JJ|NN.*>+} # Chunk sequences of DT, JJ, NN
PP: {<IN><NP>} # Chunk prepositions followed by NP
VP: {<VB.*><NP|PP|CLAUSE>+$} # Chunk verbs and their arguments
CLAUSE: {<NP><VP>} # Chunk NP, VP
"""chunk_parser = nltk.RegexpParser(grammar)
tree = chunk_parser.parse(quote_tag)
tree.pretty_print(unicodelines=True) S
┌───┬───────┬─────────┬─────┬───┬───┬────┬─────┬─────┬──────┬───┬────┬───────┬────────┬───────┬─────────┬─────────┬────────┬────────┬──────┬─────┬───────┬──────┬──────┬──────────┬────┴──────────────┬────────────────────┬──────────────────────────────────┬───────────────────────────────────┬───────────────────────┬────────────────────┬─────────────────┬───────────────────────┬───────────────────────┬────────────────────────────┐
│ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ PP PP │ │ PP │ PP │ PP
│ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ ┌──────┴─────┐ ┌────────────┴─────┐ │ │ ┌────┴────┐ │ ┌────┴──────┐ │ ┌────┴─────┐
│ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ NP NP │ NP │ NP NP NP │ NP NP │ NP NP │ NP
│ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ ┌─────┴────┐ ┌──────┴─────┐ │ ┌─────┴──────┐ │ ┌───────────┼──────────┐ ┌───────┼────────┐ ┌─────┴──────┐ │ │ ┌─────┴────────┐ │ │ ┌────────┼───────┬───────┐ │ │
,/, ,/, staring/VBG down/RP ,/, ,/, ,/, and/CC ,/, best/JJS ,/, ,/, in/IN which/WDT she/PRP could/MD wander/VB where/WRB she/PRP liked/VBD ,/, made/VBD to/TO her/PRP$ ./. The/DT dim/NN dusty/JJ room/NN with/IN the/DT busts/NNS from/IN the/DT tall/JJ book-cases/NNS the/DT cosy/JJ chairs/NNS the/DT globes/NNS of/IN all/DT the/DT wilderness/NN of/IN books/NNS the/DT library/NN a/DT region/NN of/IN bliss/NN
As you can see, the generated tree shows the chunks that were identified by the grammar rules. There also is a chink operator, which is the opposite of chunk. It allows us to remove a chunk from a larger chunk.
12.1.9 Named Entity Recognition
Previous methods have been able to identify the parts of speech of each word in a text. However, we may want to identify specific entities within the text. For example, we may want to identify the names of people, places, and organizations. nltk includes a named entity recognizer which can identify these entities. We can demonstrate this using a quote from The Iliad by Homer.
homer = "In the war of Troy, the Greeks having sacked some of the neighbouring towns, and taken from thence two beautiful captives, Chryseïs and Briseïs, allotted the first to Agamemnon, and the last to Achilles."
homer_token = word_tokenize(homer)
homer_tag = nltk.pos_tag(homer_token)#nltk.download("maxent_ne_chunker")
#nltk.download("words")
tree2 = nltk.ne_chunk(homer_tag)
tree2.pretty_print(unicodelines=True) S
┌─────┬──────┬──────┬────┬────┬────────┬──────────┬─────────┬──────┬─────┬───────────┬────────────┬──────┬────┬────────┬────────┬────────┬───────┬─────────┼────────────┬────────┬────┬─────┬───────┬─────────┬───────┬───────┬────┬────┬──────┬───────┬──────┬────┬─────┬─────────┬───────────┬────────────┬────────────┬────────────┐
│ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ GPE GPE PERSON GPE GPE GPE
│ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │
In/IN the/DT war/NN of/IN ,/, the/DT having/VBG sacked/VBN some/DT of/IN the/DT neighbouring/JJ towns/NNS ,/, and/CC taken/VBN from/IN thence/NN two/CD beautiful/JJ captives/NNS ,/, and/CC ,/, allotted/VBD the/DT first/JJ to/TO ,/, and/CC the/DT last/JJ to/TO ./. Troy/NNP Greeks/NNP Chryseïs/NNP Briseïs/NNP Agamemnon/NNP Achilles/NNP
In the tree, some of the words that should be tagged as PERSON are tagged as GPE, or Geo-Political Entity. In these cases, we can also generate a tree which does not specify the type of named entity.
tree3 = nltk.ne_chunk(homer_tag, binary=True)
tree3.pretty_print(unicodelines=True) S
┌─────┬──────┬──────┬────┬────┬────────┬──────────┬─────────┬──────┬─────┬───────────┬────────────┬──────┬────┬────────┬────────┬────────┬───────┬─────────┼────────────┬────────┬────┬─────┬───────┬─────────┬───────┬───────┬────┬────┬──────┬───────┬──────┬────┬─────┬─────────┬───────────┬────────────┬────────────┬────────────┐
│ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ NE NE NE NE NE NE
│ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │
In/IN the/DT war/NN of/IN ,/, the/DT having/VBG sacked/VBN some/DT of/IN the/DT neighbouring/JJ towns/NNS ,/, and/CC taken/VBN from/IN thence/NN two/CD beautiful/JJ captives/NNS ,/, and/CC ,/, allotted/VBD the/DT first/JJ to/TO ,/, and/CC the/DT last/JJ to/TO ./. Troy/NNP Greeks/NNP Chryseïs/NNP Briseïs/NNP Agamemnon/NNP Achilles/NNP
12.1.10 Analyzing Corpora
nltk includes a number of corpora, which are large bodies of text. We will try out some methods on the 1851 novel Moby Dick by Herman Melville.
from nltk.book import **** Introductory Examples for the NLTK Book ***
Loading text1, ..., text9 and sent1, ..., sent9
Type the name of the text or sentence to view it.
Type: 'texts()' or 'sents()' to list the materials.text1: Moby Dick by Herman Melville 1851text2: Sense and Sensibility by Jane Austen 1811
text3: The Book of Genesistext4: Inaugural Address Corpustext5: Chat Corpus
text6: Monty Python and the Holy Grailtext7: Wall Street Journal
text8: Personals Corpus
text9: The Man Who Was Thursday by G . K . Chesterton 190812.1.10.1 Concordance
concordance allows us to find all instances of a word in a text. We can use this to find all instances of the word “whale” in Moby Dick.
text1.concordance("whale")Displaying 25 of 1226 matches:
s , and to teach them by what name a whale - fish is to be called in our tongue
t which is not true ." -- HACKLUYT " WHALE . ... Sw . and Dan . HVAL . This ani
ulted ." -- WEBSTER ' S DICTIONARY " WHALE . ... It is more immediately from th
ISH . WAL , DUTCH . HWAL , SWEDISH . WHALE , ICELANDIC . WHALE , ENGLISH . BALE
HWAL , SWEDISH . WHALE , ICELANDIC . WHALE , ENGLISH . BALEINE , FRENCH . BALLE
least , take the higgledy - piggledy whale statements , however authentic , in
dreadful gulf of this monster ' s ( whale ' s ) mouth , are immediately lost a
patient Job ." -- RABELAIS . " This whale ' s liver was two cartloads ." -- ST
Touching that monstrous bulk of the whale or ork we have received nothing cert
of oil will be extracted out of one whale ." -- IBID . " HISTORY OF LIFE AND D
ise ." -- KING HENRY . " Very like a whale ." -- HAMLET . " Which to secure , n
restless paine , Like as the wounded whale to shore flies thro ' the maine ." -
. OF SPERMA CETI AND THE SPERMA CETI WHALE . VIDE HIS V . E . " Like Spencer '
t had been a sprat in the mouth of a whale ." -- PILGRIM ' S PROGRESS . " That
EN ' S ANNUS MIRABILIS . " While the whale is floating at the stern of the ship
e ship called The Jonas - in - the - Whale . ... Some say the whale can ' t ope
in - the - Whale . ... Some say the whale can ' t open his mouth , but that is
masts to see whether they can see a whale , for the first discoverer has a duc
for his pains . ... I was told of a whale taken near Shetland , that had above
oneers told me that he caught once a whale in Spitzbergen that was white all ov
2 , one eighty feet in length of the whale - bone kind came in , which ( as I w
n master and kill this Sperma - ceti whale , for I could never hear of any of t
. 1729 . "... and the breath of the whale is frequendy attended with such an i
ed with hoops and armed with ribs of whale ." -- RAPE OF THE LOCK . " If we com
contemptible in the comparison . The whale is doubtless the largest animal in c12.1.10.2 Dispersion Plot
dispersion_plot allows us to see how a word is used throughout a text. We can use this to see the representation of characters throughout Moby Dick.
text1.dispersion_plot(["Ahab", "Ishmael", "Starbuck", "Queequeg"])/usr/local/lib/python3.11/site-packages/nltk/draw/__init__.py:15: UserWarning: nltk.draw package not loaded (please install Tkinter library).
warnings.warn("nltk.draw package not loaded (please install Tkinter library).")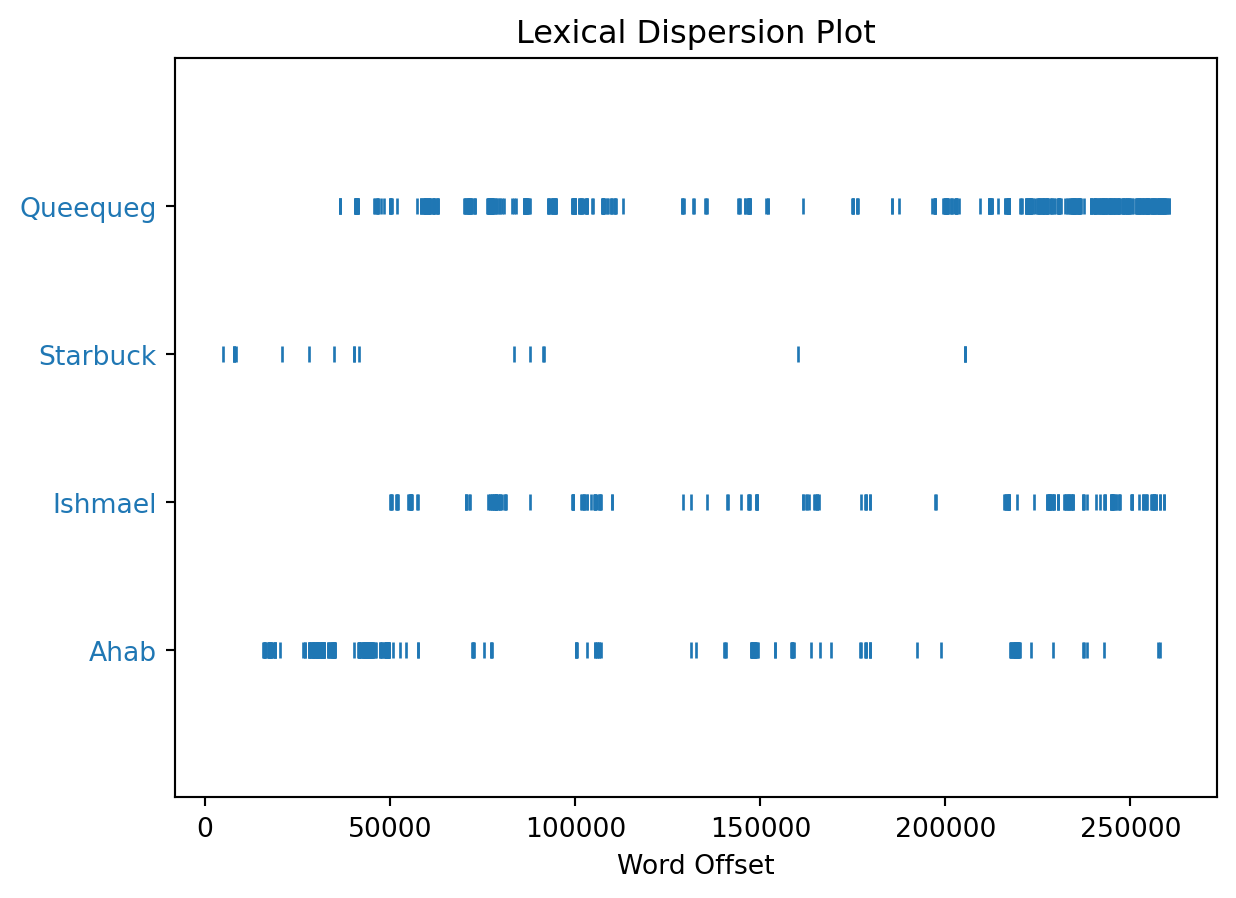
12.1.10.3 Frequency Distribution
FreqDist allows us to see the frequency of each word in a text. We can use this to see the most common words in Moby Dick.
from nltk import FreqDist
fdist1 = FreqDist(text1)
print(fdist1)<FreqDist with 19317 samples and 260819 outcomes>We can use the list of stop words generated previously to help us focus on meaningful words.
text1_imp = [w for w in text1 if w not in stop_words and w.isalpha()]
fdist2 = FreqDist(text1_imp)
fdist2.most_common(20)[('I', 2124),
('whale', 906),
('one', 889),
('But', 705),
('like', 624),
('The', 612),
('upon', 538),
('man', 508),
('ship', 507),
('Ahab', 501),
('ye', 460),
('old', 436),
('sea', 433),
('would', 421),
('And', 369),
('head', 335),
('though', 335),
('boat', 330),
('time', 324),
('long', 318)]We can visualize the frequency distribution using plot.
fdist2.plot(20, cumulative=True)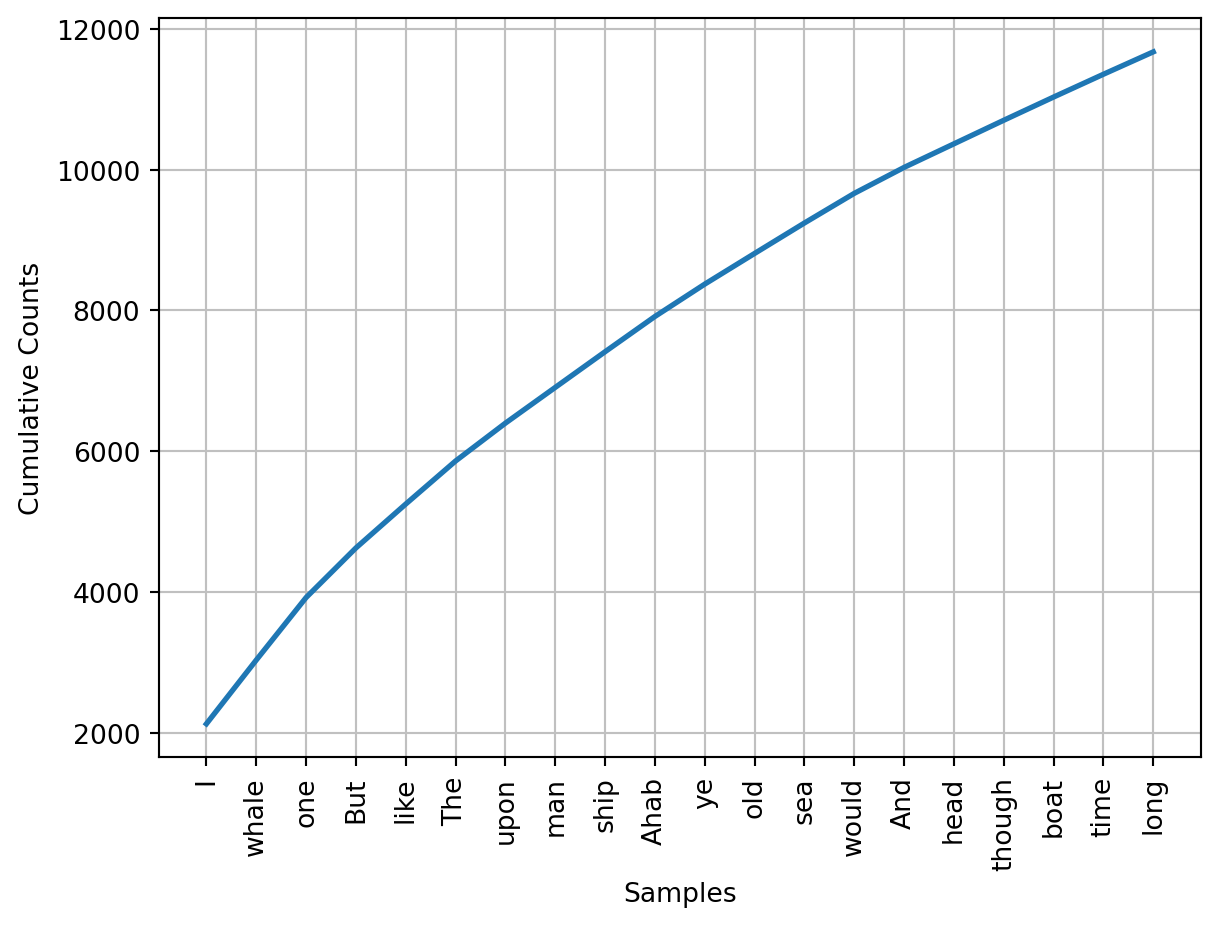
<AxesSubplot: xlabel='Samples', ylabel='Cumulative Counts'>12.1.10.4 Collocations
collocations allows us to find words that commonly appear together. We can use this to find the most common collocations in Moby Dick.
text1.collocations()Sperm Whale; Moby Dick; White Whale; old man; Captain Ahab; sperm
whale; Right Whale; Captain Peleg; New Bedford; Cape Horn; cried Ahab;
years ago; lower jaw; never mind; Father Mapple; cried Stubb; chief
mate; white whale; ivory leg; one hand12.1.11 Conclusion
In this tutorial, we have learned how to use nltk to perform basic text analysis. There are many methods included in this package that help provide structure to text. These methods can be used in conjunction with other packages to perform more complex analysis. For example, a dataframe of open-ended customer feedback could be processed to identify common themes, as well as the polarity of the feedback.
12.1.12 Resources
12.2 Neural Networks with Tensorflow (by Giovanni Lunetta)
A neural network is a type of machine learning algorithm that is inspired by the structure and function of the human brain. It consists of layers of interconnected nodes, or neurons, that can learn to recognize patterns in data and make predictions or decisions based on that input.
Neural networks are used in a wide variety of applications, including image and speech recognition, natural language processing, predictive analytics, robotics, and more. They have been especially effective in tasks that require pattern recognition, such as identifying objects in images, translating between languages, and predicting future trends in data.
12.2.1 Neural Network Architecture
A neural network consists of one or more layers of neurons, each of which takes input from the previous layer and produces output for the next layer. The input layer receives raw data, while the output layer produces predictions or decisions based on that input. The hidden layers in between contain neurons that can learn to recognize patterns in the data and extract features that are useful for making predictions.
Each neuron in a neural network has a set of weights and biases that determine how it responds to input. These values are adjusted during training to improve the accuracy of the network’s predictions. The activation function of a neuron determines how it responds to input, such as by applying a threshold or sigmoid function.
Code
from IPython.display import Image
# Image(filename='ai-artificial-neural-network-alex-castrounis.png')The input layer: The three blue nodes on the left side of the diagram represent the input layer. This layer receives input data, such as pixel values from an image or numerical features from a dataset.
The hidden layer: The four white nodes in the middle of the diagram represent the hidden layer. This layer performs computations on the input data and generates output values that are passed to the output layer.
The output layer: The orange node on the right side of the diagram represents the output layer. This layer generates the final output of the neural network, which can be a binary classification (0 or 1) or a continuous value.
The arrows: The arrows in the diagram represent the connections between nodes in adjacent layers. Each arrow has an associated weight, which is a parameter learned during the training process. The weights determine the strength of the connections between the nodes and are used to compute the output values of each node.
12.2.2 ReLu Activation Function
The ReLU (Rectified Linear Unit) activation function is used in neural networks to introduce non-linearity into the model. Non-linearity allows neural networks to learn more complex relationships between inputs and outputs.
ReLU is a simple function that returns the input if it is positive, and 0 otherwise. This means that ReLU “activates” (returns a non-zero output) only if the input is positive, which can be thought of as a way for the neuron to “turn on” when the input is significant enough. In contrast, a linear function would simply scale the input by a constant factor, which would not introduce any non-linearity into the model.
In simple terms, ReLU allows the neural network to selectively activate certain neurons based on the importance of the input, which helps it learn more complex patterns in the data.
import numpy as np
import matplotlib.pyplot as plt
def linear(x):
return x
def relu(x):
return np.maximum(0, x)
x = np.linspace(-10, 10, 100)
y_linear = linear(x)
y_relu = relu(x)
plt.plot(x, y_linear, label='Linear')
plt.plot(x, y_relu, label='ReLU')
plt.legend()
plt.xlabel('Input')
plt.ylabel('Output')
plt.show()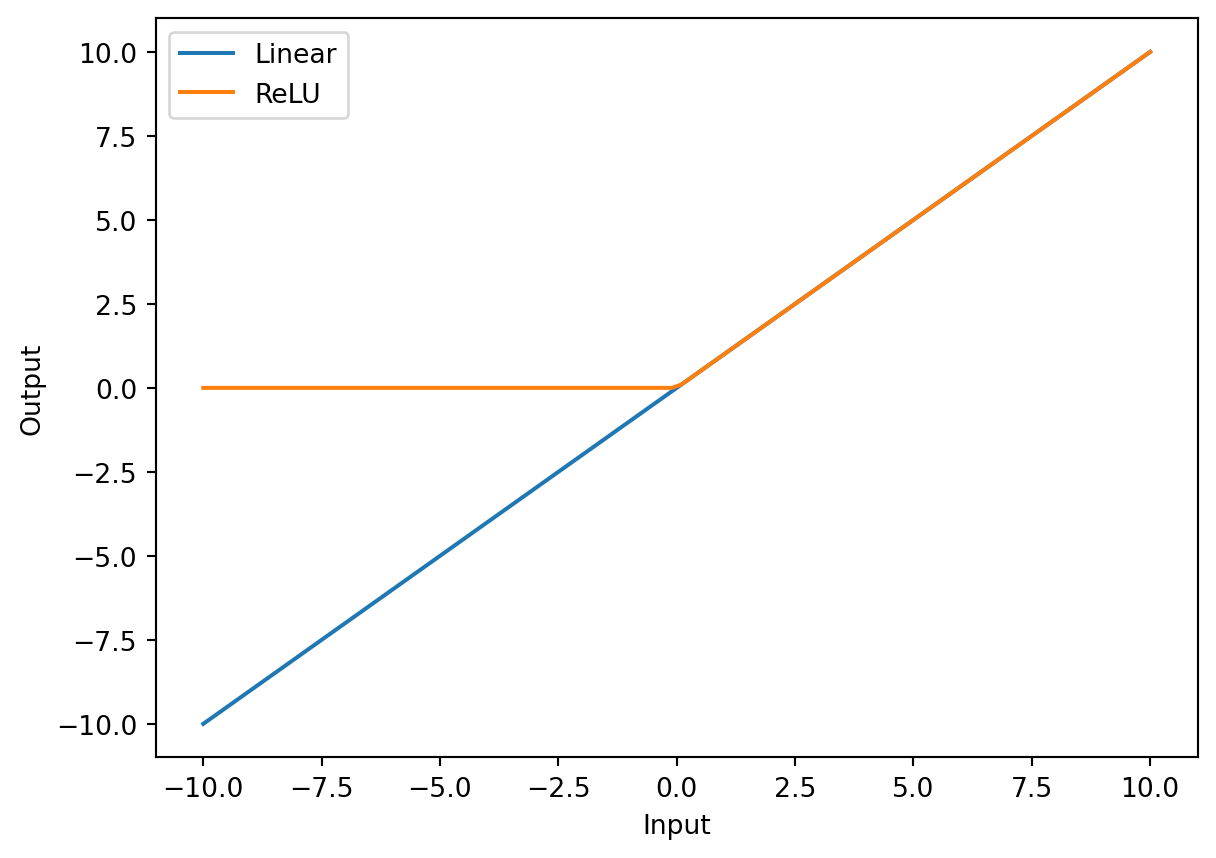
12.2.3 Demonstration
TensorFlow is an open-source software library developed by Google that is widely used for building and training machine learning models, including neural networks. TensorFlow provides a range of tools and abstractions that make it easier to build and optimize complex models, as well as tools for deploying models in production.
Here’s an example of how to use TensorFlow to build a neural network for a softmax regression model:
First we start by importing the proper packages:
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.utils import plot_model
from tensorflow.keras.losses import SparseCategoricalCrossentropy
import numpy as np
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt2023-04-10 20:47:18.379479: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.
To enable the following instructions: AVX2 FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.TensorFlow and Keras are closely related, as Keras is a high-level API that is built on top of TensorFlow. Keras provides a user-friendly interface for building neural networks, making it easy to create, train, and evaluate models without needing to know the details of TensorFlow’s low-level API.
Keras was initially developed as a standalone library, but since version 2.0, it has been integrated into TensorFlow as its official high-level API. This means that Keras can now be used as a part of TensorFlow, providing a unified and comprehensive platform for deep learning.
In other words, Keras is essentially a wrapper around TensorFlow that provides a simpler and more intuitive interface for building neural networks. While TensorFlow provides a lower-level API that offers more control and flexibility, Keras makes it easier to get started with building deep learning models, especially for beginners.
# make dataset for example
centers = [[-5, 2], [-2, -2], [1, 2], [5, -2]]
X_train, y_train = make_blobs(n_samples=2000, centers=centers, cluster_std=2.0,random_state=75)
# plot the example dataset
plt.scatter(X_train[:, 0], X_train[:, 1], c=y_train)
plt.title('Example Dataset')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()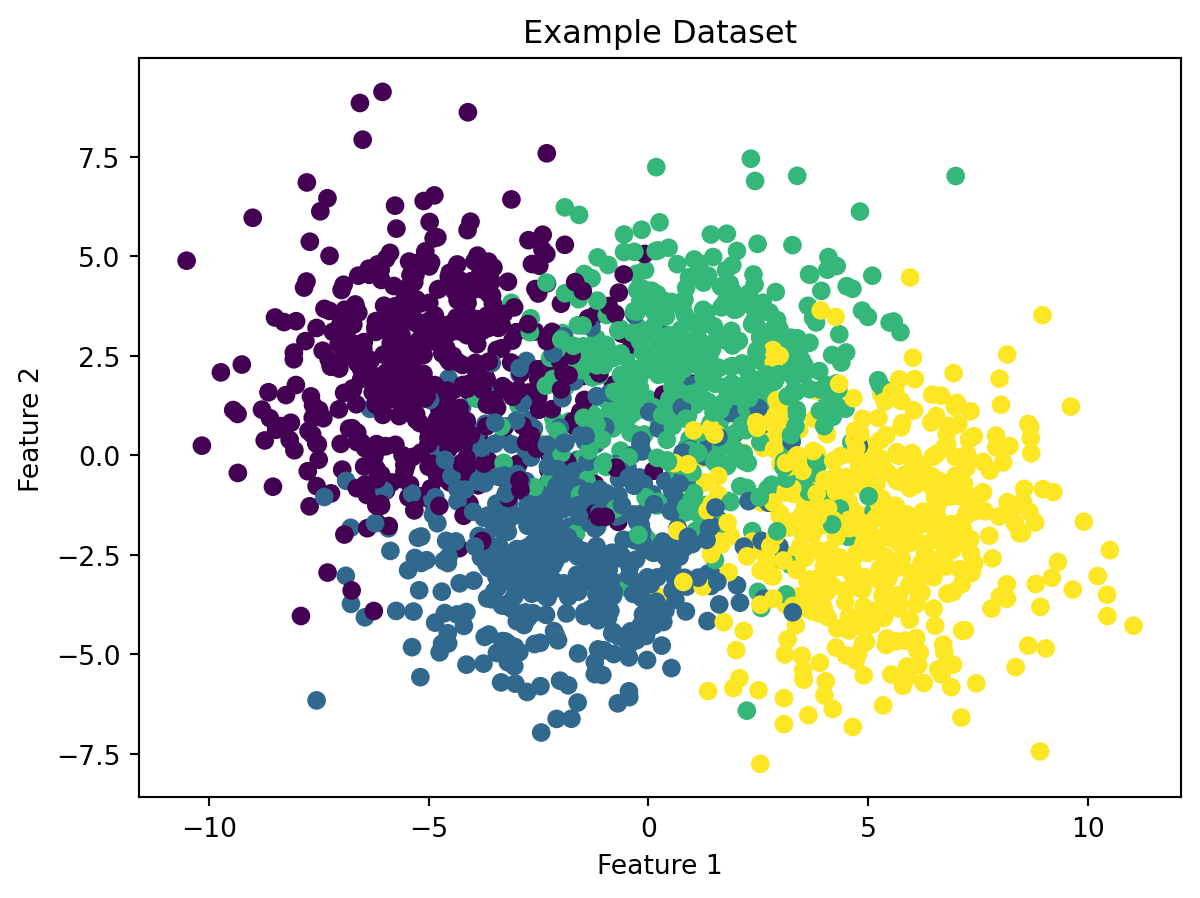
We will talk about three ways to implement a softmax regression machine learning model. The first using Stochastic Gradient Descent as the loss function. Next, using a potentially more efficient algoritm called the Adam Algoritm. Finally, using the Adam Algoritm again, but more efficiently.
12.2.3.1 Stochastic Gradient Descent
sgd_model = tf.keras.Sequential([
Dense(10, activation = 'relu'),
Dense(5, activation = 'relu'),
Dense(4, activation = 'softmax') # <-- softmax activation here
]
)
sgd_model.compile(
loss=tf.keras.losses.SparseCategoricalCrossentropy(), # <-- Note
)
sgd_history = sgd_model.fit(
X_train,y_train,
epochs=30
)Epoch 1/30 1/63 [..............................] - ETA: 38s - loss: 1.772035/63 [===============>..............] - ETA: 0s - loss: 1.4569 63/63 [==============================] - 1s 1ms/step - loss: 1.3344Epoch 2/30 1/63 [..............................] - ETA: 0s - loss: 1.265842/63 [===================>..........] - ETA: 0s - loss: 1.001163/63 [==============================] - 0s 1ms/step - loss: 0.9616Epoch 3/30 1/63 [..............................] - ETA: 0s - loss: 0.966349/63 [======================>.......] - ETA: 0s - loss: 0.807463/63 [==============================] - 0s 1ms/step - loss: 0.7756Epoch 4/30 1/63 [..............................] - ETA: 0s - loss: 0.779248/63 [=====================>........] - ETA: 0s - loss: 0.690063/63 [==============================] - 0s 1ms/step - loss: 0.6672Epoch 5/30 1/63 [..............................] - ETA: 0s - loss: 0.599549/63 [======================>.......] - ETA: 0s - loss: 0.604063/63 [==============================] - 0s 1ms/step - loss: 0.6121Epoch 6/30 1/63 [..............................] - ETA: 0s - loss: 0.446249/63 [======================>.......] - ETA: 0s - loss: 0.577063/63 [==============================] - 0s 1ms/step - loss: 0.5784Epoch 7/30 1/63 [..............................] - ETA: 0s - loss: 0.713049/63 [======================>.......] - ETA: 0s - loss: 0.552063/63 [==============================] - 0s 1ms/step - loss: 0.5533Epoch 8/30 1/63 [..............................] - ETA: 0s - loss: 0.523245/63 [====================>.........] - ETA: 0s - loss: 0.518663/63 [==============================] - 0s 1ms/step - loss: 0.5324Epoch 9/30 1/63 [..............................] - ETA: 0s - loss: 0.877246/63 [====================>.........] - ETA: 0s - loss: 0.522663/63 [==============================] - 0s 1ms/step - loss: 0.5147Epoch 10/30 1/63 [..............................] - ETA: 0s - loss: 0.553046/63 [====================>.........] - ETA: 0s - loss: 0.491263/63 [==============================] - 0s 1ms/step - loss: 0.4989Epoch 11/30 1/63 [..............................] - ETA: 0s - loss: 0.382047/63 [=====================>........] - ETA: 0s - loss: 0.491463/63 [==============================] - 0s 1ms/step - loss: 0.4848Epoch 12/30 1/63 [..............................] - ETA: 0s - loss: 0.538847/63 [=====================>........] - ETA: 0s - loss: 0.467763/63 [==============================] - 0s 1ms/step - loss: 0.4727Epoch 13/30 1/63 [..............................] - ETA: 0s - loss: 0.558647/63 [=====================>........] - ETA: 0s - loss: 0.467463/63 [==============================] - 0s 1ms/step - loss: 0.4623Epoch 14/30 1/63 [..............................] - ETA: 0s - loss: 0.567547/63 [=====================>........] - ETA: 0s - loss: 0.432963/63 [==============================] - 0s 1ms/step - loss: 0.4523Epoch 15/30 1/63 [..............................] - ETA: 0s - loss: 0.460646/63 [====================>.........] - ETA: 0s - loss: 0.439063/63 [==============================] - 0s 1ms/step - loss: 0.4448Epoch 16/30 1/63 [..............................] - ETA: 0s - loss: 0.516149/63 [======================>.......] - ETA: 0s - loss: 0.461363/63 [==============================] - 0s 1ms/step - loss: 0.4384Epoch 17/30 1/63 [..............................] - ETA: 0s - loss: 0.549849/63 [======================>.......] - ETA: 0s - loss: 0.442463/63 [==============================] - 0s 1ms/step - loss: 0.4326Epoch 18/30 1/63 [..............................] - ETA: 0s - loss: 0.319649/63 [======================>.......] - ETA: 0s - loss: 0.435063/63 [==============================] - 0s 1ms/step - loss: 0.4280Epoch 19/30 1/63 [..............................] - ETA: 0s - loss: 0.492650/63 [======================>.......] - ETA: 0s - loss: 0.420463/63 [==============================] - 0s 1ms/step - loss: 0.4238Epoch 20/30 1/63 [..............................] - ETA: 0s - loss: 0.379350/63 [======================>.......] - ETA: 0s - loss: 0.408563/63 [==============================] - 0s 1ms/step - loss: 0.4200Epoch 21/30 1/63 [..............................] - ETA: 0s - loss: 0.339549/63 [======================>.......] - ETA: 0s - loss: 0.413963/63 [==============================] - 0s 1ms/step - loss: 0.4169Epoch 22/30 1/63 [..............................] - ETA: 0s - loss: 0.321136/63 [================>.............] - ETA: 0s - loss: 0.413461/63 [============================>.] - ETA: 0s - loss: 0.414263/63 [==============================] - 0s 2ms/step - loss: 0.4144Epoch 23/30 1/63 [..............................] - ETA: 0s - loss: 0.528834/63 [===============>..............] - ETA: 0s - loss: 0.422163/63 [==============================] - 0s 1ms/step - loss: 0.4126Epoch 24/30 1/63 [..............................] - ETA: 0s - loss: 0.444848/63 [=====================>........] - ETA: 0s - loss: 0.413363/63 [==============================] - 0s 1ms/step - loss: 0.4105Epoch 25/30 1/63 [..............................] - ETA: 0s - loss: 0.486849/63 [======================>.......] - ETA: 0s - loss: 0.404763/63 [==============================] - 0s 1ms/step - loss: 0.4084Epoch 26/30 1/63 [..............................] - ETA: 0s - loss: 0.387948/63 [=====================>........] - ETA: 0s - loss: 0.412363/63 [==============================] - 0s 1ms/step - loss: 0.4062Epoch 27/30 1/63 [..............................] - ETA: 0s - loss: 0.386249/63 [======================>.......] - ETA: 0s - loss: 0.419463/63 [==============================] - 0s 1ms/step - loss: 0.4044Epoch 28/30 1/63 [..............................] - ETA: 0s - loss: 0.464450/63 [======================>.......] - ETA: 0s - loss: 0.405263/63 [==============================] - 0s 1ms/step - loss: 0.4031Epoch 29/30 1/63 [..............................] - ETA: 0s - loss: 0.352749/63 [======================>.......] - ETA: 0s - loss: 0.396263/63 [==============================] - 0s 1ms/step - loss: 0.4023Epoch 30/30 1/63 [..............................] - ETA: 0s - loss: 0.531649/63 [======================>.......] - ETA: 0s - loss: 0.399463/63 [==============================] - 0s 1ms/step - loss: 0.4012Here is a step-by-step explanation of the code:
First, we create a sequential model using the
tf.keras.Sequential()function. This is a linear stack of layers where we can add layers using the.add()method.Then we add three dense layers to the model using the
.add()method. The first two layers have the relu activation function and the last layer has the softmax activation function.We import
SparseCategoricalCrossentropyfromtensorflow.keras.losses. This is our loss function, which will be used to evaluate the model during training.We compile the model using
model.compile(), specifying theSparseCategoricalCrossentropy()as our loss function.We fit the model to the training data using
model.fit(), specifying the training data (X_train and y_train) and the number of epochs* (10).
In summary, the code creates a sequential model with three dense layers, using the relu activation function in the first two layers and the softmax activation function in the output layer. The model is then compiled using the SparseCategoricalCrossentropy() loss function, and finally, the model is trained for 10 epochs using the model.fit() method.
*In machine learning, the term “epochs” refers to the number of times the entire training dataset is used to train the model. During each epoch, the model processes the entire dataset, updates its parameters based on the computed errors, and moves on to the next epoch until the desired level of accuracy is achieved. Increasing the number of epochs may improve the model accuracy, but it also increases the risk of overfitting on the training data. Therefore, the number of epochs is a hyperparameter that must be tuned to achieve the best possible results.
sgd_model.summary()Model: "sequential"_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= dense (Dense) (None, 10) 30 dense_1 (Dense) (None, 5) 55 dense_2 (Dense) (None, 4) 24 =================================================================Total params: 109Trainable params: 109Non-trainable params: 0_________________________________________________________________In this example, the first hidden layer has 10 neurons, so there are 10 * 3 = 30 parameters (3 input features). The second hidden layer has 5 neurons, so there are 5 * 10 + 5 = 55 parameters (10 inputs from the previous layer, plus 5 bias terms). The output layer has 4 neurons, so there are 5 * 4 + 4 = 24 parameters (5 inputs from the previous layer, plus 4 bias terms).
The output None for the total number of trainable parameters means that none of the layers have been marked as non-trainable.
The None values in the output shape column represent the variable batch size that is inputted during the training process.
p_nonpreferred = sgd_model.predict(X_train)
print(p_nonpreferred [:2])
print("largest value", np.max(p_nonpreferred), "smallest value", np.min(p_nonpreferred)) 1/63 [..............................] - ETA: 4s61/63 [============================>.] - ETA: 0s63/63 [==============================] - 0s 857us/step[[3.0265430e-05 9.9000406e-01 7.7044405e-03 2.2612682e-03]
[9.8559028e-09 2.8865002e-03 4.3772280e-02 9.5334125e-01]]
largest value 0.9999842 smallest value 1.1022385e-20p_nonpreferred = model.predict(X_train): This line uses the predict method of the model object to make predictions on the input data X_train. The resulting predictions are stored in the p_nonpreferred variable.
print(p_nonpreferred [:2]): This line prints the first two rows of p_nonpreferred. Each row represents the predicted probabilities for a single observation in the training set. The four columns represent the predicted probabilities for each of the four classes in the dataset.
print("largest value", np.max(p_nonpreferred), "smallest value", np.min(p_nonpreferred)): This line prints out the largest and smallest values from p_nonpreferred, which can give an idea of the range of the predictions. The np.max and np.min functions from NumPy are used to find the maximum and minimum values in p_nonpreferred.
The output is a matrix with two rows (because we have two input examples) and four columns (because the output layer has four neurons). Each element of the matrix is the probability that the input example belongs to the corresponding class. For example, the probability that the first input example belongs to class 3 (which has the highest probability) is 0.99254191.
12.2.3.2 ADAM Algoritm
adam_model = Sequential(
[
Dense(25, activation = 'relu'),
Dense(15, activation = 'relu'),
Dense(4, activation = 'softmax') # < softmax activation here
]
)
adam_model.compile(
loss=tf.keras.losses.SparseCategoricalCrossentropy(),
optimizer=tf.keras.optimizers.Adam(0.001), # < change to 0.01 and rerun
)
adam_history = adam_model.fit(
X_train,y_train,
epochs=30
)Epoch 1/30 1/63 [..............................] - ETA: 29s - loss: 2.122746/63 [====================>.........] - ETA: 0s - loss: 1.4394 63/63 [==============================] - 1s 1ms/step - loss: 1.3151Epoch 2/30 1/63 [..............................] - ETA: 0s - loss: 0.922443/63 [===================>..........] - ETA: 0s - loss: 0.767863/63 [==============================] - 0s 1ms/step - loss: 0.7279Epoch 3/30 1/63 [..............................] - ETA: 0s - loss: 0.591349/63 [======================>.......] - ETA: 0s - loss: 0.559963/63 [==============================] - 0s 1ms/step - loss: 0.5584Epoch 4/30 1/63 [..............................] - ETA: 0s - loss: 0.508749/63 [======================>.......] - ETA: 0s - loss: 0.508463/63 [==============================] - 0s 1ms/step - loss: 0.5000Epoch 5/30 1/63 [..............................] - ETA: 0s - loss: 0.500348/63 [=====================>........] - ETA: 0s - loss: 0.475863/63 [==============================] - 0s 1ms/step - loss: 0.4721Epoch 6/30 1/63 [..............................] - ETA: 0s - loss: 0.264348/63 [=====================>........] - ETA: 0s - loss: 0.465063/63 [==============================] - 0s 1ms/step - loss: 0.4582Epoch 7/30 1/63 [..............................] - ETA: 0s - loss: 0.547547/63 [=====================>........] - ETA: 0s - loss: 0.449463/63 [==============================] - 0s 1ms/step - loss: 0.4458Epoch 8/30 1/63 [..............................] - ETA: 0s - loss: 0.360547/63 [=====================>........] - ETA: 0s - loss: 0.439463/63 [==============================] - 0s 1ms/step - loss: 0.4361Epoch 9/30 1/63 [..............................] - ETA: 0s - loss: 0.428948/63 [=====================>........] - ETA: 0s - loss: 0.433763/63 [==============================] - 0s 1ms/step - loss: 0.4278Epoch 10/30 1/63 [..............................] - ETA: 0s - loss: 0.593248/63 [=====================>........] - ETA: 0s - loss: 0.426563/63 [==============================] - 0s 1ms/step - loss: 0.4206Epoch 11/30 1/63 [..............................] - ETA: 0s - loss: 0.390547/63 [=====================>........] - ETA: 0s - loss: 0.401563/63 [==============================] - 0s 1ms/step - loss: 0.4156Epoch 12/30 1/63 [..............................] - ETA: 0s - loss: 0.327547/63 [=====================>........] - ETA: 0s - loss: 0.404963/63 [==============================] - 0s 1ms/step - loss: 0.4085Epoch 13/30 1/63 [..............................] - ETA: 0s - loss: 0.458248/63 [=====================>........] - ETA: 0s - loss: 0.404663/63 [==============================] - 0s 1ms/step - loss: 0.4050Epoch 14/30 1/63 [..............................] - ETA: 0s - loss: 0.329747/63 [=====================>........] - ETA: 0s - loss: 0.418163/63 [==============================] - 0s 1ms/step - loss: 0.4021Epoch 15/30 1/63 [..............................] - ETA: 0s - loss: 0.393148/63 [=====================>........] - ETA: 0s - loss: 0.386763/63 [==============================] - 0s 1ms/step - loss: 0.4025Epoch 16/30 1/63 [..............................] - ETA: 0s - loss: 0.341040/63 [==================>...........] - ETA: 0s - loss: 0.413463/63 [==============================] - 0s 1ms/step - loss: 0.3997Epoch 17/30 1/63 [..............................] - ETA: 0s - loss: 0.273448/63 [=====================>........] - ETA: 0s - loss: 0.384963/63 [==============================] - 0s 1ms/step - loss: 0.3969Epoch 18/30 1/63 [..............................] - ETA: 0s - loss: 0.336647/63 [=====================>........] - ETA: 0s - loss: 0.395563/63 [==============================] - 0s 1ms/step - loss: 0.3970Epoch 19/30 1/63 [..............................] - ETA: 0s - loss: 0.487848/63 [=====================>........] - ETA: 0s - loss: 0.386863/63 [==============================] - 0s 1ms/step - loss: 0.3957Epoch 20/30 1/63 [..............................] - ETA: 0s - loss: 0.297047/63 [=====================>........] - ETA: 0s - loss: 0.398063/63 [==============================] - 0s 1ms/step - loss: 0.3939Epoch 21/30 1/63 [..............................] - ETA: 0s - loss: 0.406147/63 [=====================>........] - ETA: 0s - loss: 0.404763/63 [==============================] - 0s 1ms/step - loss: 0.3944Epoch 22/30 1/63 [..............................] - ETA: 0s - loss: 0.229547/63 [=====================>........] - ETA: 0s - loss: 0.383863/63 [==============================] - 0s 1ms/step - loss: 0.3931Epoch 23/30 1/63 [..............................] - ETA: 0s - loss: 0.479748/63 [=====================>........] - ETA: 0s - loss: 0.394163/63 [==============================] - 0s 1ms/step - loss: 0.3928Epoch 24/30 1/63 [..............................] - ETA: 0s - loss: 0.625347/63 [=====================>........] - ETA: 0s - loss: 0.378963/63 [==============================] - 0s 1ms/step - loss: 0.3931Epoch 25/30 1/63 [..............................] - ETA: 0s - loss: 0.345247/63 [=====================>........] - ETA: 0s - loss: 0.389663/63 [==============================] - 0s 1ms/step - loss: 0.3923Epoch 26/30 1/63 [..............................] - ETA: 0s - loss: 0.269447/63 [=====================>........] - ETA: 0s - loss: 0.411463/63 [==============================] - 0s 1ms/step - loss: 0.3926Epoch 27/30 1/63 [..............................] - ETA: 0s - loss: 0.381548/63 [=====================>........] - ETA: 0s - loss: 0.387463/63 [==============================] - 0s 1ms/step - loss: 0.3908Epoch 28/30 1/63 [..............................] - ETA: 0s - loss: 0.524448/63 [=====================>........] - ETA: 0s - loss: 0.386563/63 [==============================] - 0s 1ms/step - loss: 0.3920Epoch 29/30 1/63 [..............................] - ETA: 0s - loss: 0.406548/63 [=====================>........] - ETA: 0s - loss: 0.408663/63 [==============================] - 0s 1ms/step - loss: 0.3931Epoch 30/30 1/63 [..............................] - ETA: 0s - loss: 0.367348/63 [=====================>........] - ETA: 0s - loss: 0.379063/63 [==============================] - 0s 1ms/step - loss: 0.3907adam_model.summary()Model: "sequential_1"_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= dense_3 (Dense) (None, 25) 75 dense_4 (Dense) (None, 15) 390 dense_5 (Dense) (None, 4) 64 =================================================================Total params: 529Trainable params: 529Non-trainable params: 0_________________________________________________________________The None values in the output shape column represent the variable batch size that is inputted during the training process. The number of parameters in each layer depends on the number of inputs and the number of neurons in the layer, along with any additional bias terms.
In this example, the first hidden layer has 25 neurons, so there are 25 * 3 = 75 parameters (3 input features). The second hidden layer has 15 neurons, so there are 15 * 25 + 15 = 390 parameters (25 inputs from the previous layer, plus 15 bias terms). The output layer has 4 neurons, so there are 15 * 4 + 4 = 64 parameters (15 inputs from the previous layer, plus 4 bias terms).
The output None for the total number of trainable parameters means that none of the layers have been marked as non-trainable.
p_nonpreferred = adam_model.predict(X_train)
print(p_nonpreferred [:2])
print("largest value", np.max(p_nonpreferred), "smallest value", np.min(p_nonpreferred)) 1/63 [..............................] - ETA: 2s60/63 [===========================>..] - ETA: 0s63/63 [==============================] - 0s 866us/step[[3.7956154e-03 9.6981263e-01 1.5898595e-02 1.0493187e-02]
[4.6749294e-05 3.6971366e-03 6.8161853e-02 9.2809433e-01]]
largest value 0.999983 smallest value 1.492862e-13Here, the only difference between the these two machine learning models is the optimizer. That line of code, optimizer=tf.keras.optimizers.Adam(0.001), specifies the optimizer to be used during training. In this case, it uses the Adam optimizer with a learning rate of 0.001. The Adam optimizer is an adaptive optimization algorithm that is commonly used in deep learning for its ability to dynamically adjust the learning rate during training, which can help prevent the model from getting stuck in local minima.
Code
import numpy as np
import matplotlib.pyplot as plt
# Define the objective function (quadratic)
def objective(x, y):
return x**2 + y**2
# Define the Adam update rule
def adam_update(x, y, m, v, t, alpha=0.1, beta1=0.9, beta2=0.999, eps=1e-8):
g = np.array([2*x, 2*y])
m = beta1 * m + (1 - beta1) * g
v = beta2 * v + (1 - beta2) * g**2
m_hat = m / (1 - beta1**t)
v_hat = v / (1 - beta2**t)
dx = - alpha * m_hat[0] / (np.sqrt(v_hat[0]) + eps)
dy = - alpha * m_hat[1] / (np.sqrt(v_hat[1]) + eps)
return dx, dy, m, v
# Define the parameters for the optimization
theta = np.array([2.0, 2.0])
m = np.zeros(2)
v = np.zeros(2)
t = 0
alpha = 0.1
beta1 = 0.9
beta2 = 0.999
eps = 1e-8
# Generate the parameter space grid
x = np.linspace(-3, 3, 100)
y = np.linspace(-3, 3, 100)
X, Y = np.meshgrid(x, y)
Z = objective(X, Y)
# Generate the parameter space plot
fig, ax = plt.subplots()
ax.contour(X, Y, Z, levels=30, cmap='jet')
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_title('Parameter Space of Adam')
# Perform several iterations of Adam and plot the updates
for i in range(20):
t += 1
dx, dy, m, v = adam_update(theta[0], theta[1], m, v, t, alpha, beta1, beta2, eps)
theta += np.array([dx, dy])
ax.arrow(theta[0]-dx, theta[1]-dy, dx, dy, head_width=0.1, head_length=0.1, fc='b', ec='b')
plt.show()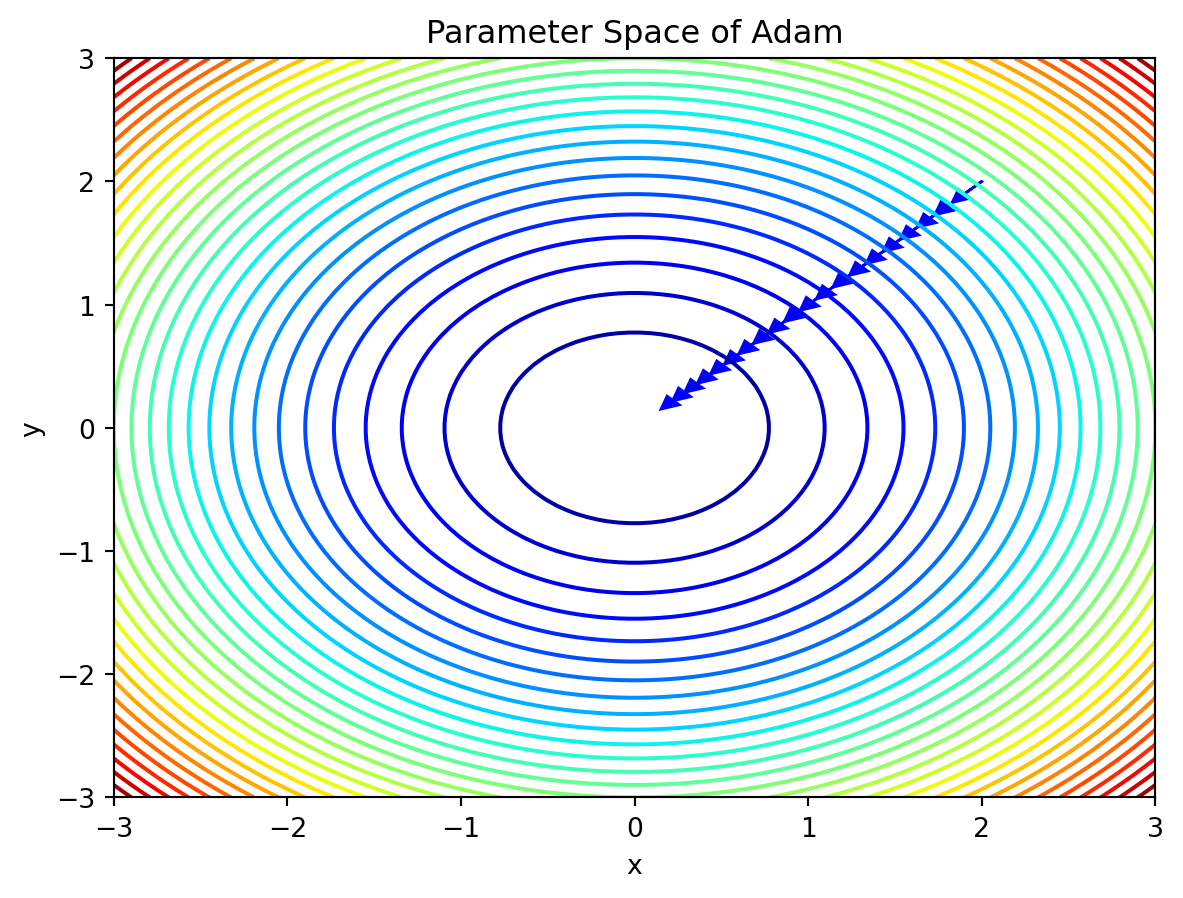
plt.plot(sgd_history.history['loss'], label='SGD')
plt.plot(adam_history.history['loss'], label='Adam')
plt.legend()
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.show()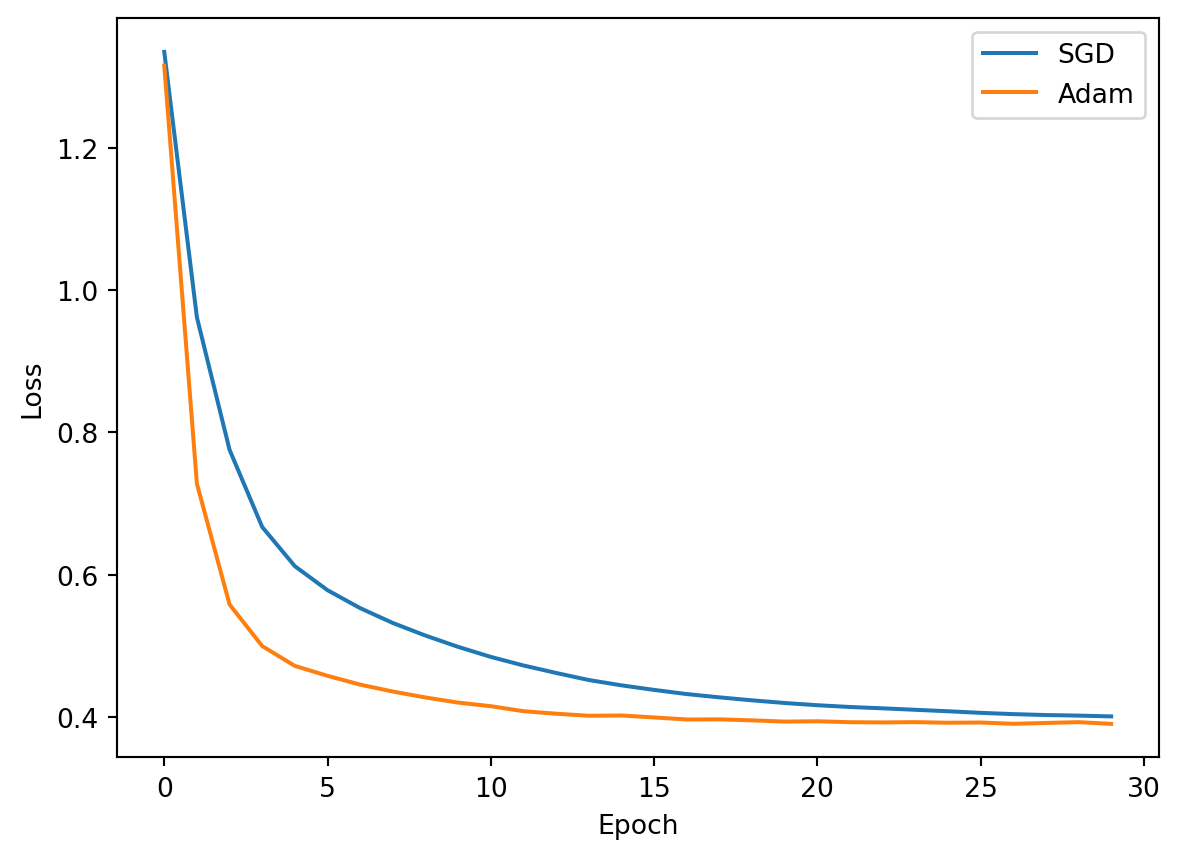
12.2.3.3 Preferred ADAM Algorithm
As we have talked about in class before, numerical roundoff errors happen when coding in python due to memory overflow.
x1 = 2.0 / 10000
print(f"{x1:.18f}") # print 18 digits to the right of the decimal point0.000200000000000000x2 = 1 + (1/10000) - (1 - 1/10000)
print(f"{x2:.18f}")0.000199999999999978It turns out that while the implementation of the loss function for softmax was correct, there is a different and better way of reducing numerical roundoff errors which leads to more accurate computations.
If we go back to how a loss function for softmax regression is implemented we see that the loss function is expressed in the following formula: \[ \text{loss}(a_1, a_2, \dots, a_n, y) = \begin{cases} -\log(a_1) & \text{if } y = 1 \\ -\log(a_2) & \text{if } y = 2 \\ \vdots & \vdots \\ -\log(a_n) & \text{if } y = n \end{cases} \]
where \(a_j\) is computed from: \[ a_j = \frac{e^{z_j}}{\sum\limits_{k=1}^n e^{z_k}} = P(y=j \mid \vec{x}) \]
This can lead to numerical roundoff errors in tensorflow as the loss function is not directly computing \(a_j\).
In terms of code, that is exactly what loss=SparseCategoricalCrossentropy() is doing. Therefore, it would be more accurate if we could implement the loss function as follows: \[
\text{loss}(a_1, a_2, \dots, a_n, y) =
\begin{cases}
-\log(\frac{e^{z_1}}{e^{z_1} + e^{z_2} + ... + e^{z_n}}) & \text{if } y = 1 \\
-\log(\frac{e^{z_2}}{e^{z_1} + e^{z_2} + ... + e^{z_n}}) & \text{if } y = 2 \\
\vdots & \vdots \\
-\log(\frac{e^{z_j}}{\sum\limits_{k=1}^n e^{z_k}}) & \text{if } y = n
\end{cases}
\]
We achieve this in two steps. The first is making the output layer a linear activation, and additionally adding a from_logits=True parameter to the loss=tf.keras.losses.SparseCategoricalCrossentropy line of code. By using a linear activation function instead of softmax, the model will output a vector of real numbers rather than probabilities.
preferred_model = Sequential(
[
Dense(25, activation = 'relu'),
Dense(15, activation = 'relu'),
Dense(4, activation = 'linear') #<-- Note
]
)
preferred_model.compile(
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), #<-- Note
optimizer=tf.keras.optimizers.Adam(0.001),
)
preferred_history = preferred_model.fit(
X_train,y_train,
epochs=30
)Epoch 1/30 1/63 [..............................] - ETA: 28s - loss: 1.785048/63 [=====================>........] - ETA: 0s - loss: 1.1980 63/63 [==============================] - 1s 1ms/step - loss: 1.1161Epoch 2/30 1/63 [..............................] - ETA: 0s - loss: 0.664348/63 [=====================>........] - ETA: 0s - loss: 0.663563/63 [==============================] - 0s 1ms/step - loss: 0.6332Epoch 3/30 1/63 [..............................] - ETA: 0s - loss: 0.549549/63 [======================>.......] - ETA: 0s - loss: 0.508263/63 [==============================] - 0s 1ms/step - loss: 0.5024Epoch 4/30 1/63 [..............................] - ETA: 0s - loss: 0.384547/63 [=====================>........] - ETA: 0s - loss: 0.462463/63 [==============================] - 0s 1ms/step - loss: 0.4612Epoch 5/30 1/63 [..............................] - ETA: 0s - loss: 0.425635/63 [===============>..............] - ETA: 0s - loss: 0.436663/63 [==============================] - 0s 1ms/step - loss: 0.4412Epoch 6/30 1/63 [..............................] - ETA: 0s - loss: 0.600737/63 [================>.............] - ETA: 0s - loss: 0.440563/63 [==============================] - 0s 1ms/step - loss: 0.4306Epoch 7/30 1/63 [..............................] - ETA: 0s - loss: 0.529241/63 [==================>...........] - ETA: 0s - loss: 0.428163/63 [==============================] - 0s 1ms/step - loss: 0.4233Epoch 8/30 1/63 [..............................] - ETA: 0s - loss: 0.234535/63 [===============>..............] - ETA: 0s - loss: 0.411263/63 [==============================] - 0s 2ms/step - loss: 0.4162Epoch 9/30 1/63 [..............................] - ETA: 0s - loss: 0.368437/63 [================>.............] - ETA: 0s - loss: 0.413063/63 [==============================] - 0s 1ms/step - loss: 0.4114Epoch 10/30 1/63 [..............................] - ETA: 0s - loss: 0.544645/63 [====================>.........] - ETA: 0s - loss: 0.413263/63 [==============================] - 0s 1ms/step - loss: 0.4089Epoch 11/30 1/63 [..............................] - ETA: 0s - loss: 0.416345/63 [====================>.........] - ETA: 0s - loss: 0.410963/63 [==============================] - 0s 1ms/step - loss: 0.4047Epoch 12/30 1/63 [..............................] - ETA: 0s - loss: 0.448946/63 [====================>.........] - ETA: 0s - loss: 0.399863/63 [==============================] - 0s 1ms/step - loss: 0.4031Epoch 13/30 1/63 [..............................] - ETA: 0s - loss: 0.460248/63 [=====================>........] - ETA: 0s - loss: 0.397463/63 [==============================] - 0s 1ms/step - loss: 0.4015Epoch 14/30 1/63 [..............................] - ETA: 0s - loss: 0.453247/63 [=====================>........] - ETA: 0s - loss: 0.402863/63 [==============================] - 0s 1ms/step - loss: 0.3983Epoch 15/30 1/63 [..............................] - ETA: 0s - loss: 0.673846/63 [====================>.........] - ETA: 0s - loss: 0.381463/63 [==============================] - 0s 1ms/step - loss: 0.3974Epoch 16/30 1/63 [..............................] - ETA: 0s - loss: 0.404247/63 [=====================>........] - ETA: 0s - loss: 0.399163/63 [==============================] - 0s 1ms/step - loss: 0.3970Epoch 17/30 1/63 [..............................] - ETA: 0s - loss: 0.404149/63 [======================>.......] - ETA: 0s - loss: 0.399863/63 [==============================] - 0s 1ms/step - loss: 0.3951Epoch 18/30 1/63 [..............................] - ETA: 0s - loss: 0.338347/63 [=====================>........] - ETA: 0s - loss: 0.387763/63 [==============================] - 0s 1ms/step - loss: 0.3955Epoch 19/30 1/63 [..............................] - ETA: 0s - loss: 0.643848/63 [=====================>........] - ETA: 0s - loss: 0.401863/63 [==============================] - 0s 1ms/step - loss: 0.3941Epoch 20/30 1/63 [..............................] - ETA: 0s - loss: 0.184448/63 [=====================>........] - ETA: 0s - loss: 0.395763/63 [==============================] - 0s 1ms/step - loss: 0.3931Epoch 21/30 1/63 [..............................] - ETA: 0s - loss: 0.233847/63 [=====================>........] - ETA: 0s - loss: 0.388463/63 [==============================] - 0s 1ms/step - loss: 0.3910Epoch 22/30 1/63 [..............................] - ETA: 0s - loss: 0.300148/63 [=====================>........] - ETA: 0s - loss: 0.402563/63 [==============================] - 0s 1ms/step - loss: 0.3906Epoch 23/30 1/63 [..............................] - ETA: 0s - loss: 0.572948/63 [=====================>........] - ETA: 0s - loss: 0.397963/63 [==============================] - 0s 1ms/step - loss: 0.3931Epoch 24/30 1/63 [..............................] - ETA: 0s - loss: 0.553847/63 [=====================>........] - ETA: 0s - loss: 0.395863/63 [==============================] - 0s 1ms/step - loss: 0.3909Epoch 25/30 1/63 [..............................] - ETA: 0s - loss: 0.373347/63 [=====================>........] - ETA: 0s - loss: 0.405263/63 [==============================] - 0s 1ms/step - loss: 0.3908Epoch 26/30 1/63 [..............................] - ETA: 0s - loss: 0.342443/63 [===================>..........] - ETA: 0s - loss: 0.397463/63 [==============================] - 0s 1ms/step - loss: 0.3890Epoch 27/30 1/63 [..............................] - ETA: 0s - loss: 0.320645/63 [====================>.........] - ETA: 0s - loss: 0.388663/63 [==============================] - 0s 1ms/step - loss: 0.3918Epoch 28/30 1/63 [..............................] - ETA: 0s - loss: 0.588740/63 [==================>...........] - ETA: 0s - loss: 0.398363/63 [==============================] - 0s 1ms/step - loss: 0.3898Epoch 29/30 1/63 [..............................] - ETA: 0s - loss: 0.437342/63 [===================>..........] - ETA: 0s - loss: 0.360963/63 [==============================] - 0s 1ms/step - loss: 0.3899Epoch 30/30 1/63 [..............................] - ETA: 0s - loss: 0.197347/63 [=====================>........] - ETA: 0s - loss: 0.403463/63 [==============================] - 0s 1ms/step - loss: 0.3897p_preferred = preferred_model.predict(X_train)
print(f"two example output vectors:\n {p_preferred[:2]}")
print("largest value", np.max(p_preferred), "smallest value", np.min(p_preferred)) 1/63 [..............................] - ETA: 2s61/63 [============================>.] - ETA: 0s63/63 [==============================] - 0s 862us/steptwo example output vectors:
[[-0.6257403 5.117499 0.07288799 1.0743215 ]
[-2.9822855 0.81028026 3.5368693 6.0620565 ]]
largest value 18.288116 smallest value -6.9841967Notice that in the preferred model, the outputs are not probabilities, but can range from large negative numbers to large positive numbers. The output must be sent through a softmax when performing a prediction that expects a probability.
If the desired output are probabilities, the output should be be processed by a softmax.
sm_preferred = tf.nn.softmax(p_preferred).numpy()
print(f"two example output vectors:\n {sm_preferred[:2]}")
print("largest value", np.max(sm_preferred), "smallest value", np.min(sm_preferred))two example output vectors:
[[3.11955088e-03 9.73529756e-01 6.27339305e-03 1.70773119e-02]
[1.08768334e-04 4.82606189e-03 7.37454817e-02 9.21319604e-01]]
largest value 0.999989 smallest value 1.80216e-11This code applies the softmax activation function to the output of a neural network model p_preferred, and then converts the resulting tensor to a numpy array using the .numpy() method. The resulting array sm_preferred contains the probabilities for each of the possible output classes for the input data.
The second line of code then prints the first two rows of sm_preferred, which correspond to the probabilities for the first two input examples in the dataset.
Lets check the loss functions one final time:
plt.plot(adam_history.history['loss'], label='ADAM')
plt.plot(preferred_history.history['loss'], label='Pref_ADAM')
plt.plot(sgd_history.history['loss'], label='SGD')
plt.legend()
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.show()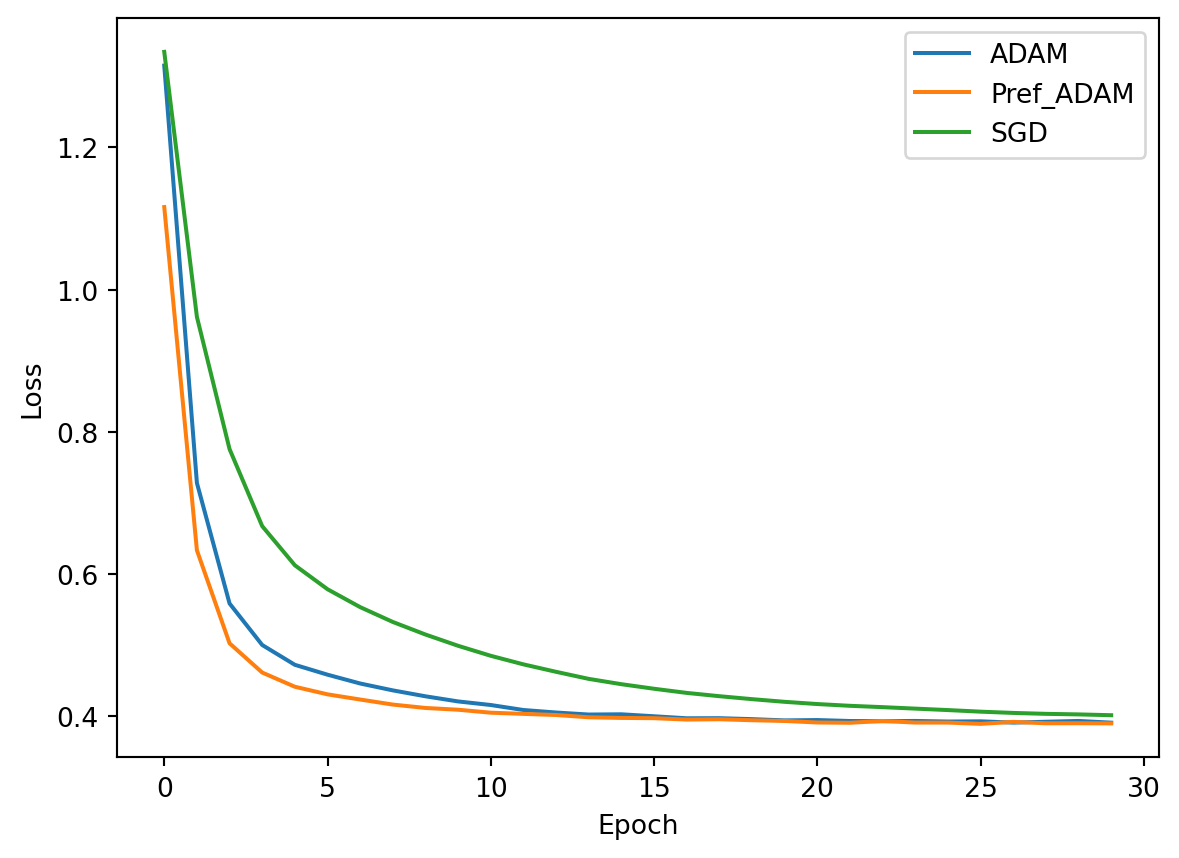
12.2.4 References
- https://www.tensorflow.org/api_docs/python/tf/nn/softmax
- https://www.tensorflow.org/
- https://www.whyofai.com/blog/ai-explained
- https://www.coursera.org/specializations/machine-learning-introduction
12.3 Web Scraping with Selenium (by Michael Zheng)
Selenium is a free, open-source automation testing suite for web applications across different browsers and platforms. Selenium focuses on automating web-based applications.
12.3.1 Selenium vs BeautifulSoup?
Selenium is a web browser automation tool that can interact with web pages like a human user, whereas BeautifulSoup is a library for parsing HTML and XML documents. This means Selenium has more functionality since it can automate browser actions such as clicking buttons, filling out forms and navigating between pages.
However, Selenium is not as fast as BeautifulSoup. Thus, if your web scraping problem can be solved with BeautifulSoup, use that.
An example of a website that can’t be scraped by BeautifulSoup is a website that doesn’t fully load unless prompted to: https://www.inaturalist.org/taxa/52083-Toxicodendron-pubescens/browse_photos?layout=grid.
- Go to the link and inspect the first photo
- Collapse the ‘TaxonPhoto undefined’ div container and scroll to the last ‘TaxonPhoto undefined’
- Go back to the web page and scroll down to load new images
See those ‘TaxonPhoto undefined’ elements that are popping up on the right side of the screen as we scroll? Those are more photos that are being rendered as we directly interact with the web page. BeautifulSoup can only scrape HTML elements from what’s already loaded on the web page. It cannot dynamically interact with the page to load more HTML elements. Luckily, Selenium can do that!
12.3.2 Example: Plant Images Scraper
I will demonstrate the functionalities of Selenium by building a program to scrape plant images from a website. Hopefully, this example will be enough for anybody listening to get started with Selenium.
12.3.2.1 Components of a Website
Websites are developed using 3 main languages: javascript, html, and css.
We don’t need to get too much into what each of these languages do, but just know that html tells a browser how to display the content of a website; and that is what we will interact with to extract data from the website.
12.3.2.2 HTML
In HTML, the contents of a website are organized into containers called div.
These div containers are given identifiers using class and id
<div class="widget"></div>In this example, the div container is given the class name “widget”.
<div id="widget"></div>In this example, the div container is given the id name “widget”.
We can use the find_elements method in Selenium to retrieve the containers that we want by using their XPATH, which is the address to the containers specified in the HTML file.
Say we want to retrieve all the “widget” containers on a web page. Then, we can use the find_elements method. The method can locate containers based on many techniques, but we want to specify By.XPATH here. Then we want to locate the containers whose ids have the name “widget”; we can do this with classes as well by replacing @id with @class.
find_elements(By.XPATH, "//*[starts-with(@id, 'widget')]")12.3.2.3 Additional Selenium Functionalities
Selenium is very powerful and contains many useful features for interacting with browsers. We will not be using most of them in this project, but they’re still good to know.
As we mentioned earlier, find_elements will retrieve all specified elements on the page. But there is also find_element, note that element is singular, which will only return one element of the specified type; the first one that it comes across.
Besides XPATH, there are other techniques for locating div containers. For instance, we can also use:
# Find the element with name "my-element"
element = driver.find_element(By.NAME, 'my-element')
# Find the element with ID "my-element"
element = driver.find_element(By.ID, 'my-element')
# Find the element with class name "my-element"
element = driver.find_element(By.CLASS_NAME, 'my-element')
# Find the element with CSS selector "#my-element .my-class"
element = driver.find_element(By.CSS_SELECTOR, '#my-element .my-class')==========================================================================================
You can also interact with text fields in browsers via Selenium.
Say you are automating a scraper that needs to login to a website. Well we know how to find the elements using the find_element method:
# Find the username and password fields
username_field = driver.find_element(By.NAME, 'username')
password_field = driver.find_element(By.NAME, 'password')Now those two variables are pointing to the corresponding text fields on the page. So, we can enter in our username and password by using the send_keys method:
username_field.send_keys('myusername')
password_field.send_keys('mypassword')To complete the login, we need to click on the login button. We can do this by using the click method:
# Find the login button and click it
login_button = driver.find_element(By.XPATH, '//button[@type="submit"]')
login_button.click()==========================================================================================
Sometimes you may need to wait for an element to appear on the page before you can interact with it. You can do this using the WebDriverWait class provided by Selenium. For example:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
search_results = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.ID, 'search')))Selenium will wait for a maximum of 10 seconds for the element with the id “search” to appear on the page. If 10 seconds pass and the element doesn’t appear, then an error will be returned. Otherwise, the driver will retrieve the element and store it in the variable search_results.
Now that we have an understanding of how to interact with HTML elements using Selenium. Let’s get started with building the program!
- Step 1: Import Libraries
import time # will be used to allow sufficient time for web pages to load
import requests # will be used to send requests to web pages to download images
# selenium functions
from selenium import webdriver # how selenium uses the browser on your laptop
from selenium.webdriver.chrome.service import Service # tells selenium what browser to use
from webdriver_manager.chrome import ChromeDriverManager # a package to manage chrome driver dependencies so you don't have to
from selenium.webdriver.common.by import By # method for using XPATHS to locate div elements- Step 2: Scrape Image Links
Let’s make a plan for how we are gonna scrape these images:
Go to this link:
https://www.inaturalist.org/taxa/52083-Toxicodendron-pubescens/browse_photos?layout=gridScroll down; notice how the page takes some time to load more images (this is where the ‘time’ library will come into play)
Right click on a picture and Inspect
Navigate to the div container with id that starts with ‘cover-image…’
Notice that the images are stored in a AWS S3 data lake with the link to the image encapsulated by url(…)
Copy and paste the link into browser to open the image
But another important point, the image url is mixed in with a bunch of other text; starts with “width: 100%…” (so we need to remove all the text surrounding the link)
Let’s define a function called image_links_scraper. It’s job will be to extract the image links for each image on the website. It will take in 2 parameters: link = link to the website that we wanna scrape and max_images = total number of images we wanna scrape
def image_links_scraper(link, max_images):
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
# 1. downloads the latest google chrome driver (executable that selenium uses to launch google chrome)
# 2. service is responsible for starting the webdriver, an interface for interacting with browsers, using the chrome driver
# 3. once the webdriver is started, we can use it to interact with chrome
# whenever we want to interact with the browser we call a method from driver
driver.get(link)
# get method opens the browser to the specified link
image_links = []
# we will store the scraped image links in this list
### ISSUE (step 2) ###
current_height = driver.execute_script("return document.body.scrollHeight")
# executes a javascript command to get the current height of the page (which is the length of the page from the top to the bottom before it loads new images)
while True: # keep scrolling down on the browser to load new images until we reach the end of the page
driver.execute_script(f"window.scrollTo({current_height}, document.body.scrollHeight);")
# run javascript command to scroll to the bottom of the page
elements = driver.find_elements(By.XPATH, "//*[starts-with(@id, 'cover')]")
# find all elements where the 'id' tag starts with the string 'cover' because these div containers have the image links
if len(elements) >= max_images: # check to see if we have scraped enough image links, as specified by the max_images parameter
break # if so, stop scolling
time.sleep(5)
# wait for page to load; dependent on internet speed
new_height = driver.execute_script("return document.body.scrollHeight")
# get new page height after scrolling
if current_height == new_height: # check to see if the page height has stopped changing
break # if so, we've reached the end of the page and need to stop scrolling
else:
current_height = new_height # otherwise, we need to keep scrolling
# at this point, we have not scraped any images
# we only have the div container elements that contain the image links we want to extract
# now we go through each element and extract the links
for element in elements:
# ### ISSUE (step 7) ###
s = element.get_attribute('style')
# returns the text in the 'style' attribute
start = 'width: 100%; min-height: 183px; background-size: cover; background-position: center center; background-repeat: no-repeat; background-image: url("'
# the useless text before the link
end = '");'
# the useless text after the link
link = s[len(start):-len(end)]
# perform string splicing to get only the URL from the entire string
image_links.append(link)
# add the image link to the list
print(link)
# print the links as we extract them to visualize function in real-time
driver.quit()
# once we're done automating the browser, we should close it using the quit() method of the driver object
return image_links- Step 3: Download the Images
Now, we take the image links extracted from the previous step and download the images located at each link.
Let’s define a method called download_images that takes in 2 parameters: image_links = whatever image_links_scraper returns and folder_name = name of the folder to save the scraped images to
def download_images(image_links, folder_name):
i = 1 # keep track of the image number to give each image an identifier
for link in image_links: # iterate through all the image links
r = requests.get(link).content # retrieve the image content from URL by sending a request to the website
file_name = f'{folder_name}/{i}.jpg' # generate image file name (image number) and directory
with open(file_name, 'wb') as f:
f.write(r) # save the image
i += 1 # update the image number for the next iteration- Step 4: Run Everything All Together
The result is a dataset of plant images saved in a folder called _selenium_download.
# if __name__ == '__main__':
link = 'https://www.inaturalist.org/taxa/52083-Toxicodendron-pubescens/browse_photos?layout=grid' # website to scrape images from
max_images = 20 # number of images to scrape
folder_name = '_selenium_download' # name of folder to save images to
image_links = image_links_scraper(link, max_images)
download_images(image_links, folder_name)https://inaturalist-open-data.s3.amazonaws.com/photos/2418087/medium.jpg
https://inaturalist-open-data.s3.amazonaws.com/photos/7400447/medium.jpg
https://inaturalist-open-data.s3.amazonaws.com/photos/7400452/medium.jpg
https://inaturalist-open-data.s3.amazonaws.com/photos/148667986/medium.jpeg
https://inaturalist-open-data.s3.amazonaws.com/photos/148667997/medium.jpeg
https://inaturalist-open-data.s3.amazonaws.com/photos/148668006/medium.jpeg
https://inaturalist-open-data.s3.amazonaws.com/photos/148668015/medium.jpeg
https://inaturalist-open-data.s3.amazonaws.com/photos/148668025/medium.jpeg
https://inaturalist-open-data.s3.amazonaws.com/photos/148668036/medium.jpeg
https://inaturalist-open-data.s3.amazonaws.com/photos/148668042/medium.jpeg
https://inaturalist-open-data.s3.amazonaws.com/photos/148668053/medium.jpeg
https://inaturalist-open-data.s3.amazonaws.com/photos/148668061/medium.jpeg
https://inaturalist-open-data.s3.amazonaws.com/photos/148668071/medium.jpeg
https://inaturalist-open-data.s3.amazonaws.com/photos/148668077/medium.jpeg
https://inaturalist-open-data.s3.amazonaws.com/photos/148668090/medium.jpeg
https://static.inaturalist.org/photos/114478526/medium.jpg
https://inaturalist-open-data.s3.amazonaws.com/photos/122630561/medium.jpeg
https://inaturalist-open-data.s3.amazonaws.com/photos/122630572/medium.jpeghttps://inaturalist-open-data.s3.amazonaws.com/photos/122630582/medium.jpeg
https://inaturalist-open-data.s3.amazonaws.com/photos/122630593/medium.jpeg
https://inaturalist-open-data.s3.amazonaws.com/photos/101461689/medium.jpg
https://inaturalist-open-data.s3.amazonaws.com/photos/194174354/medium.jpg
https://inaturalist-open-data.s3.amazonaws.com/photos/194174425/medium.jpg
https://inaturalist-open-data.s3.amazonaws.com/photos/51452451/medium.jpeg
https://inaturalist-open-data.s3.amazonaws.com/photos/51455593/medium.jpeg
https://inaturalist-open-data.s3.amazonaws.com/photos/51455616/medium.jpeg
https://inaturalist-open-data.s3.amazonaws.com/photos/51455665/medium.jpeg
https://inaturalist-open-data.s3.amazonaws.com/photos/98405618/medium.jpg
https://inaturalist-open-data.s3.amazonaws.com/photos/101535531/medium.jpg
https://inaturalist-open-data.s3.amazonaws.com/photos/101535544/medium.jpg
https://inaturalist-open-data.s3.amazonaws.com/photos/150810477/medium.jpeghttps://inaturalist-open-data.s3.amazonaws.com/photos/163894686/medium.jpg