K Nearest Neighbor
Contents
10.16. K Nearest Neighbor¶
10.16.1. Algorithm/Concept¶
The (k) nearest neighbor algorithm is a supervised learning method based on the idea that that closer data points are more similar, and is commonly used in both regression and classification. In practice, this can be used to estimate missing information or predict new variables.
In the regression case, values are predicted from an average of the k values closest to the data. For example, if you wanted to predict the weight of a new subject based on their height, from the k heights closest to them you would take the average of their weights as the subject’s weight.
For classification, assignment is based on a majority rule. If .55\(k\) of the \(k\) data points belong to Group A, the new point will also be classified as Group A.
Basic Implementation:
Choose an arbitrary value for k (often between 5 and 10).
Fit the data to the classification or regression model.
Using the k nearest training data points, categorize or predict the value of the new data point.
Optimize k value from the training data and created model.
10.16.2. Unsupervised Nearest Neighbor¶
While we focus on the supervised methodology, there is also an unsupervised version which uses
different algorithms (brute force, ball_tree, or kd_tree) to find the k nearest neighbors, where
efficiency is based on number of sample, value of k, data structure, etc.
In Python: sklearn.neighbors.NearestNeighbors
Notes:
An issue with k nearest neighbor is that if there is a significant difference in the number of observations in each group, then larger classes to to overpower smaller ones. The most common solution is to weight each observation, such that closer observations hold more deciding power than those further away. While this is especially problematic in classification, weights can be applied to regression aswell.
The algorithm is also very sensitive to the value of k. A particularly small value of k increases the liklihood of overfitting the to the training data, and too large a k reduces the accuracy of the model all around. The model should be optimized for a value of k that minimizes error rate (RMSE or MSE).
Categorical data would need to be encoded - converted into numerical data before use.
In Python, the scikit-learn library contains multiple packages to implement the k nearest neighbor algorithm in Python. The example below uses:
model_selection, neighbors, and metrics
10.16.3. Classification Example (Supervised)¶
import pandas as pd
url = \
'https://raw.githubusercontent.com/statds/ids-s22/main/notes/data/nyc_DobJobApp_2021.csv'
dob_job = pd.read_csv(url)
dob_job.info()
/tmp/ipykernel_3769/3937316007.py:6: DtypeWarning: Columns (23,24,25,26,29,31,32,59,60) have mixed types. Specify dtype option on import or set low_memory=False.
dob_job = pd.read_csv(url)
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 20087 entries, 0 to 20086
Data columns (total 96 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Job # 20087 non-null int64
1 Doc # 20087 non-null int64
2 Borough 20087 non-null object
3 House # 20087 non-null object
4 Street Name 20087 non-null object
5 Block 20087 non-null int64
6 Lot 20087 non-null int64
7 Bin # 20087 non-null int64
8 Job Type 20087 non-null object
9 Job Status 20087 non-null object
10 Job Status Descrp 20087 non-null object
11 Latest Action Date 20087 non-null object
12 Building Type 20087 non-null object
13 Community - Board 20086 non-null float64
14 Cluster 19926 non-null object
15 Landmarked 20067 non-null object
16 Adult Estab 19961 non-null object
17 Loft Board 19956 non-null object
18 City Owned 2382 non-null object
19 Little e 19930 non-null object
20 PC Filed 40 non-null object
21 eFiling Filed 19874 non-null object
22 Plumbing 1357 non-null object
23 Mechanical 756 non-null object
24 Boiler 142 non-null object
25 Fuel Burning 7 non-null object
26 Fuel Storage 25 non-null object
27 Standpipe 111 non-null object
28 Sprinkler 427 non-null object
29 Fire Alarm 209 non-null object
30 Equipment 862 non-null object
31 Fire Suppression 19 non-null object
32 Curb Cut 88 non-null object
33 Other 17420 non-null object
34 Other Description 17420 non-null object
35 Applicant's First Name 20087 non-null object
36 Applicant's Last Name 20087 non-null object
37 Applicant Professional Title 20087 non-null object
38 Applicant License # 19685 non-null float64
39 Professional Cert 20062 non-null object
40 Pre- Filing Date 20087 non-null object
41 Paid 20087 non-null object
42 Fully Paid 20087 non-null object
43 Assigned 18368 non-null object
44 Approved 20087 non-null object
45 Fully Permitted 20087 non-null object
46 Initial Cost 20087 non-null object
47 Total Est. Fee 20087 non-null object
48 Fee Status 20087 non-null object
49 Existing Zoning Sqft 20087 non-null int64
50 Proposed Zoning Sqft 20087 non-null int64
51 Horizontal Enlrgmt 769 non-null object
52 Vertical Enlrgmt 585 non-null object
53 Enlargement SQ Footage 20087 non-null int64
54 Street Frontage 20087 non-null int64
55 ExistingNo. of Stories 20087 non-null int64
56 Proposed No. of Stories 20087 non-null int64
57 Existing Height 20087 non-null int64
58 Proposed Height 20087 non-null int64
59 Existing Dwelling Units 14441 non-null object
60 Proposed Dwelling Units 14603 non-null object
61 Existing Occupancy 16999 non-null object
62 Proposed Occupancy 17211 non-null object
63 Site Fill 17656 non-null object
64 Zoning Dist1 20077 non-null object
65 Zoning Dist2 1509 non-null object
66 Zoning Dist3 71 non-null object
67 Special District 1 3087 non-null object
68 Special District 2 4241 non-null object
69 Owner Type 20087 non-null object
70 Non-Profit 20087 non-null object
71 Owner's First Name 20087 non-null object
72 Owner's Last Name 20085 non-null object
73 Owner's Business Name 11325 non-null object
74 Owner's House Number 0 non-null float64
75 Owner'sHouse Street Name 0 non-null float64
76 City 0 non-null float64
77 State 0 non-null float64
78 Zip 0 non-null float64
79 Owner'sPhone # 20087 non-null int64
80 Job Description 17609 non-null object
81 DOBRunDate 20087 non-null object
82 JOB_S1_NO 20087 non-null int64
83 TOTAL_CONSTRUCTION_FLOOR_AREA 20087 non-null int64
84 WITHDRAWAL_FLAG 20087 non-null int64
85 SIGNOFF_DATE 6598 non-null object
86 SPECIAL_ACTION_STATUS 19934 non-null object
87 SPECIAL_ACTION_DATE 36 non-null object
88 BUILDING_CLASS 19998 non-null object
89 JOB_NO_GOOD_COUNT 20087 non-null int64
90 GIS_LATITUDE 19974 non-null float64
91 GIS_LONGITUDE 19974 non-null float64
92 GIS_COUNCIL_DISTRICT 19974 non-null float64
93 GIS_CENSUS_TRACT 19974 non-null float64
94 GIS_NTA_NAME 19974 non-null object
95 GIS_BIN 19351 non-null float64
dtypes: float64(12), int64(18), object(66)
memory usage: 14.7+ MB
In the below example, we will be using a subset of the DOB Job Application dataset, for plumbing jobs that occurred in family homes.
plumbing_job = dob_job[(dob_job['Plumbing'] == 'X') &
(dob_job['Building Type'] == '1-2-3 FAMILY')]
plumbing_job = plumbing_job[['Total Est. Fee', 'Borough', 'Job Type', 'Job Status',
'Building Type','Latest Action Date', 'GIS_LATITUDE',
'GIS_LONGITUDE']]
plumbing_job = plumbing_job.dropna()
plumbing_job.head()
| Total Est. Fee | Borough | Job Type | Job Status | Building Type | Latest Action Date | GIS_LATITUDE | GIS_LONGITUDE | |
|---|---|---|---|---|---|---|---|---|
| 43 | $526.55 | BROOKLYN | A2 | X | 1-2-3 FAMILY | 08/05/2021 | 40.675306 | -73.930515 |
| 45 | $371.80 | QUEENS | A2 | R | 1-2-3 FAMILY | 04/29/2021 | 40.776331 | -73.912295 |
| 47 | $400.36 | QUEENS | NB | R | 1-2-3 FAMILY | 05/27/2021 | 40.759226 | -73.858075 |
| 50 | $2740.20 | MANHATTAN | A1 | R | 1-2-3 FAMILY | 04/29/2021 | 40.737608 | -74.002699 |
| 54 | $262.60 | BROOKLYN | A2 | R | 1-2-3 FAMILY | 04/29/2021 | 40.588934 | -73.988155 |
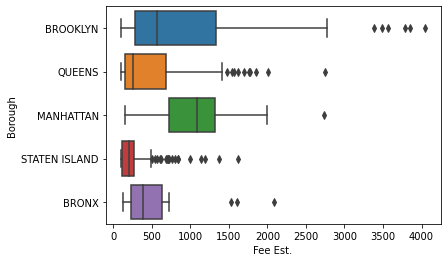
We want to try to predict the borough based on the estimated cost of the job. First we check for an association between variables.
import scipy.stats as ss
plumbing_job['Fee Est.'] = [float(val.strip('$')) for val in plumbing_job['Total Est. Fee']]
est_fee = pd.crosstab(plumbing_job['Fee Est.'], plumbing_job['Borough'])
est_fee
chi2, p, dof, ex = ss.chi2_contingency(est_fee)
p
0.0002851383836738717
import seaborn as sns
sns.boxplot(plumbing_job['Fee Est.'], plumbing_job['Borough'])
/home/runner/work/ids-s22/ids-s22/env/lib/python3.9/site-packages/seaborn/_decorators.py:36: FutureWarning: Pass the following variables as keyword args: x, y. From version 0.12, the only valid positional argument will be `data`, and passing other arguments without an explicit keyword will result in an error or misinterpretation.
warnings.warn(
<AxesSubplot:xlabel='Fee Est.', ylabel='Borough'>
name_dict = {'BROOKLYN':0, 'QUEENS':0, 'MANHATTAN':0, 'STATEN ISLAND':0, 'BRONX':0}
for key, value in name_dict.items():
new_value = plumbing_job.value_counts(plumbing_job['Borough'] == key)
name_dict[key] = new_value
name_dict
{'BROOKLYN': Borough
False 380
True 180
dtype: int64,
'QUEENS': Borough
False 335
True 225
dtype: int64,
'MANHATTAN': Borough
False 546
True 14
dtype: int64,
'STATEN ISLAND': Borough
False 446
True 114
dtype: int64,
'BRONX': Borough
False 533
True 27
dtype: int64}
Since there is a signifcant difference in the number of observations for each borough, and much of the data appears to overlap, we will create two classifiers, weighted and unweighted. This will hopefully help reduce boroughs with fewer observations from being hidden by larger boroughs.
import matplotlib.pyplot as plt
from sklearn import neighbors
from sklearn.model_selection import train_test_split
x = plumbing_job[['Fee Est.']]
y = plumbing_job['Borough']
xtrain, xtest, ytrain, ytest = train_test_split(x, y, random_state = 100)
# train_test_split = separates data into test and training subsets
knn = neighbors.KNeighborsClassifier()
knn.fit(x, y)
print(knn.predict([[750]]))
knn_weight = neighbors.KNeighborsClassifier(weights='distance')
knn_weight.fit(x, y)
print(knn_weight.predict([[750]]))
['BROOKLYN']
['QUEENS']
/home/runner/work/ids-s22/ids-s22/env/lib/python3.9/site-packages/sklearn/base.py:450: UserWarning: X does not have valid feature names, but KNeighborsClassifier was fitted with feature names
warnings.warn(
/home/runner/work/ids-s22/ids-s22/env/lib/python3.9/site-packages/sklearn/base.py:450: UserWarning: X does not have valid feature names, but KNeighborsClassifier was fitted with feature names
warnings.warn(
from sklearn.metrics import accuracy_score
predictions1 = knn.predict(xtest)
predictions2 = knn_weight.predict(xtest)
print(accuracy_score(ytest, predictions1))
print(accuracy_score(ytest, predictions2))
0.6285714285714286
0.9
This gives the prediction accuracy from the test data. Factoring in weights for the data points seems to have greatly improved the accuracy of the classification.
GridSearchCV is used to find the best k value from a dictionary of potential values. It is the alternative to calculating the validation error (RMSE) for all k. The value of k must be chosen carefully to avoid overfitting or weakened performance.
from sklearn.model_selection import GridSearchCV
pars = {'n_neighbors':[1,2,3,4,5,6,7,8,9,10]}
model = GridSearchCV(knn, pars)
model.fit(xtrain, ytrain)
model.best_params_
{'n_neighbors': 7}