Data Manipulation with Pandas
Contents
7. Data Manipulation with Pandas¶
From pandas documentation:
pandas is a Python package providing fast, flexible, and expressive data structures designed to make working with “relational” or “labeled” data both easy and intuitive. It aims to be the fundamental high-level building block for doing practical, real-world data analysis in Python. Additionally, it has the broader goal of becoming the most powerful and flexible open source data analysis/manipulation tool available in any language. It is already well on its way toward this goal.
pandas is well suited for many different kinds of data:
Tabular data with heterogeneously-typed columns, as in an SQL table or Excel spreadsheet
Ordered and unordered (not necessarily fixed-frequency) time series data
Arbitrary matrix data (homogeneously typed or heterogeneous) with row and column labels
Any other form of observational / statistical data sets. The data need not be labeled at all to be placed into a pandas data structure
7.1. Import/Export¶
import pandas as pd
nyc_crash = pd.read_csv("../data/nyc_mv_collisions_202201.csv")
nyc_crash.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 7659 entries, 0 to 7658
Data columns (total 29 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 CRASH DATE 7659 non-null object
1 CRASH TIME 7659 non-null object
2 BOROUGH 5025 non-null object
3 ZIP CODE 5025 non-null float64
4 LATITUDE 7097 non-null float64
5 LONGITUDE 7097 non-null float64
6 LOCATION 7097 non-null object
7 ON STREET NAME 5625 non-null object
8 CROSS STREET NAME 3620 non-null object
9 OFF STREET NAME 2034 non-null object
10 NUMBER OF PERSONS INJURED 7659 non-null int64
11 NUMBER OF PERSONS KILLED 7659 non-null int64
12 NUMBER OF PEDESTRIANS INJURED 7659 non-null int64
13 NUMBER OF PEDESTRIANS KILLED 7659 non-null int64
14 NUMBER OF CYCLIST INJURED 7659 non-null int64
15 NUMBER OF CYCLIST KILLED 7659 non-null int64
16 NUMBER OF MOTORIST INJURED 7659 non-null int64
17 NUMBER OF MOTORIST KILLED 7659 non-null int64
18 CONTRIBUTING FACTOR VEHICLE 1 7615 non-null object
19 CONTRIBUTING FACTOR VEHICLE 2 5624 non-null object
20 CONTRIBUTING FACTOR VEHICLE 3 824 non-null object
21 CONTRIBUTING FACTOR VEHICLE 4 225 non-null object
22 CONTRIBUTING FACTOR VEHICLE 5 80 non-null object
23 COLLISION_ID 7659 non-null int64
24 VEHICLE TYPE CODE 1 7539 non-null object
25 VEHICLE TYPE CODE 2 4748 non-null object
26 VEHICLE TYPE CODE 3 752 non-null object
27 VEHICLE TYPE CODE 4 207 non-null object
28 VEHICLE TYPE CODE 5 78 non-null object
dtypes: float64(3), int64(9), object(17)
memory usage: 1.7+ MB
Exporting data out of pandas is provided by different to_*methods.
nyc_crash.to_csv("my_nyc.csv", index=False)
7.2. View and Description¶
The head/tail/info methods and the dtypes attribute are convenient
for a first check.
Descriptive statistics for numeric variables:
nyc_crash_desc = nyc_crash.describe()
nyc_crash_desc
| ZIP CODE | LATITUDE | LONGITUDE | NUMBER OF PERSONS INJURED | NUMBER OF PERSONS KILLED | NUMBER OF PEDESTRIANS INJURED | NUMBER OF PEDESTRIANS KILLED | NUMBER OF CYCLIST INJURED | NUMBER OF CYCLIST KILLED | NUMBER OF MOTORIST INJURED | NUMBER OF MOTORIST KILLED | COLLISION_ID | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 5025.000000 | 7097.000000 | 7097.000000 | 7659.000000 | 7659.000000 | 7659.000000 | 7659.000000 | 7659.000000 | 7659.0 | 7659.000000 | 7659.000000 | 7.659000e+03 |
| mean | 10908.957015 | 40.609463 | -73.705503 | 0.404753 | 0.002350 | 0.084345 | 0.001306 | 0.021935 | 0.0 | 0.287505 | 0.000914 | 4.495510e+06 |
| std | 514.740028 | 2.160598 | 3.919451 | 0.726622 | 0.048425 | 0.290332 | 0.036113 | 0.149131 | 0.0 | 0.692545 | 0.030220 | 2.338111e+03 |
| min | 10000.000000 | 0.000000 | -74.249980 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 4.491064e+06 |
| 25% | 10459.000000 | 40.665085 | -73.960370 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 4.493532e+06 |
| 50% | 11209.000000 | 40.712505 | -73.917310 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 4.495533e+06 |
| 75% | 11354.000000 | 40.786957 | -73.862274 | 1.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 4.497480e+06 |
| max | 11697.000000 | 40.909206 | 0.000000 | 8.000000 | 1.000000 | 3.000000 | 1.000000 | 2.000000 | 0.0 | 8.000000 | 1.000000 | 4.500594e+06 |
Transpose the data:
nyc_crash_desc.T
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| ZIP CODE | 5025.0 | 1.090896e+04 | 514.740028 | 1.000000e+04 | 1.045900e+04 | 1.120900e+04 | 1.135400e+04 | 1.169700e+04 |
| LATITUDE | 7097.0 | 4.060946e+01 | 2.160598 | 0.000000e+00 | 4.066508e+01 | 4.071251e+01 | 4.078696e+01 | 4.090921e+01 |
| LONGITUDE | 7097.0 | -7.370550e+01 | 3.919451 | -7.424998e+01 | -7.396037e+01 | -7.391731e+01 | -7.386227e+01 | 0.000000e+00 |
| NUMBER OF PERSONS INJURED | 7659.0 | 4.047526e-01 | 0.726622 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 1.000000e+00 | 8.000000e+00 |
| NUMBER OF PERSONS KILLED | 7659.0 | 2.350176e-03 | 0.048425 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 1.000000e+00 |
| NUMBER OF PEDESTRIANS INJURED | 7659.0 | 8.434521e-02 | 0.290332 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 3.000000e+00 |
| NUMBER OF PEDESTRIANS KILLED | 7659.0 | 1.305653e-03 | 0.036113 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 1.000000e+00 |
| NUMBER OF CYCLIST INJURED | 7659.0 | 2.193498e-02 | 0.149131 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 2.000000e+00 |
| NUMBER OF CYCLIST KILLED | 7659.0 | 0.000000e+00 | 0.000000 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 |
| NUMBER OF MOTORIST INJURED | 7659.0 | 2.875049e-01 | 0.692545 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 8.000000e+00 |
| NUMBER OF MOTORIST KILLED | 7659.0 | 9.139574e-04 | 0.030220 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 1.000000e+00 |
| COLLISION_ID | 7659.0 | 4.495510e+06 | 2338.111464 | 4.491064e+06 | 4.493532e+06 | 4.495533e+06 | 4.497480e+06 | 4.500594e+06 |
Frequency table:
pd.crosstab(index=nyc_crash["BOROUGH"], columns = "freq")
| col_0 | freq |
|---|---|
| BOROUGH | |
| BRONX | 948 |
| BROOKLYN | 1744 |
| MANHATTAN | 737 |
| QUEENS | 1393 |
| STATEN ISLAND | 203 |
7.3. Subsetting¶
Selection by row:
brooklyn_crash = nyc_crash.loc[nyc_crash["BOROUGH"] == "BROOKLYN"]
bronx_crash = nyc_crash.loc[nyc_crash["BOROUGH"] == "BRONX"]
Selection by column:
bronx_crash[["CRASH DATE", "CRASH TIME"]]
| CRASH DATE | CRASH TIME | |
|---|---|---|
| 10 | 01/01/2022 | 16:40 |
| 18 | 01/01/2022 | 15:19 |
| 19 | 01/01/2022 | 15:00 |
| 22 | 01/01/2022 | 18:21 |
| 29 | 01/01/2022 | 1:50 |
| ... | ... | ... |
| 7628 | 01/31/2022 | 10:32 |
| 7642 | 01/31/2022 | 16:00 |
| 7643 | 01/31/2022 | 4:54 |
| 7646 | 01/31/2022 | 14:58 |
| 7657 | 01/31/2022 | 6:50 |
948 rows × 2 columns
By both
bronx_long = nyc_crash.loc[nyc_crash['BOROUGH'] == 'BRONX',
["CRASH DATE", "CRASH TIME", "LONGITUDE"]]
bronx_lat = nyc_crash.loc[nyc_crash['BOROUGH'] == 'BRONX',
["CRASH DATE", "CRASH TIME", "LATITUDE"]]
bronx_lat.head(5)
| CRASH DATE | CRASH TIME | LATITUDE | |
|---|---|---|---|
| 10 | 01/01/2022 | 16:40 | 40.806107 |
| 18 | 01/01/2022 | 15:19 | 40.833750 |
| 19 | 01/01/2022 | 15:00 | 40.858790 |
| 22 | 01/01/2022 | 18:21 | 40.890648 |
| 29 | 01/01/2022 | 1:50 | 40.895718 |
7.4. Creating new columns¶
Convert the time string to numeric for later processing:
nyc_crash["time"] = [x.split(":")[0] for x in nyc_crash["CRASH TIME"]]
nyc_crash["time"] = [int(x) for x in nyc_crash["time"]]
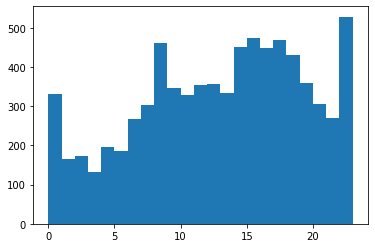
import matplotlib.pyplot as plt
plt.hist(nyc_crash["time"], bins=range(24))
(array([330., 164., 172., 131., 195., 186., 267., 304., 460., 345., 329.,
353., 357., 333., 451., 473., 447., 468., 430., 360., 306., 270.,
528.]),
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
17, 18, 19, 20, 21, 22, 23]),
<BarContainer object of 23 artists>)
7.5. Reshape¶
Sort table rows
nyc_crash.sort_values(by="time").head()
| CRASH DATE | CRASH TIME | BOROUGH | ZIP CODE | LATITUDE | LONGITUDE | LOCATION | ON STREET NAME | CROSS STREET NAME | OFF STREET NAME | ... | CONTRIBUTING FACTOR VEHICLE 3 | CONTRIBUTING FACTOR VEHICLE 4 | CONTRIBUTING FACTOR VEHICLE 5 | COLLISION_ID | VEHICLE TYPE CODE 1 | VEHICLE TYPE CODE 2 | VEHICLE TYPE CODE 3 | VEHICLE TYPE CODE 4 | VEHICLE TYPE CODE 5 | time | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 6873 | 01/28/2022 | 0:42 | NaN | NaN | NaN | NaN | NaN | ROOSEVELT AVENUE | SUBWAY QUEENS YARD | NaN | ... | NaN | NaN | NaN | 4498387 | Bike | NaN | NaN | NaN | NaN | 0 |
| 2140 | 01/09/2022 | 0:30 | NaN | NaN | 40.709633 | -73.767815 | (40.709633, -73.767815) | HOLLIS AVENUE | 99 AVENUE | NaN | ... | NaN | NaN | NaN | 4493304 | Station Wagon/Sport Utility Vehicle | Station Wagon/Sport Utility Vehicle | NaN | NaN | NaN | 0 |
| 5036 | 01/21/2022 | 0:45 | BROOKLYN | 11238.0 | 40.681780 | -73.958740 | (40.68178, -73.95874) | NaN | NaN | 1079 FULTON STREET | ... | NaN | NaN | NaN | 4496106 | Sedan | Station Wagon/Sport Utility Vehicle | NaN | NaN | NaN | 0 |
| 5026 | 01/21/2022 | 0:34 | NaN | NaN | 40.741447 | -73.846030 | (40.741447, -73.84603) | GRAND CENTRAL PKWY | NaN | NaN | ... | NaN | NaN | NaN | 4496199 | Station Wagon/Sport Utility Vehicle | NaN | NaN | NaN | NaN | 0 |
| 5016 | 01/21/2022 | 0:15 | BROOKLYN | 11215.0 | 40.660576 | -73.990650 | (40.660576, -73.99065) | 6 AVENUE | 20 STREET | NaN | ... | NaN | NaN | NaN | 4496310 | Sedan | Station Wagon/Sport Utility Vehicle | NaN | NaN | NaN | 0 |
5 rows × 30 columns
Pivot table (long to wide)
nyc_crash.pivot_table(
values = ["LATITUDE", "LONGITUDE"],
index = "BOROUGH",
aggfunc = "mean",
margins = True)
| LATITUDE | LONGITUDE | |
|---|---|---|
| BOROUGH | ||
| BRONX | 40.715739 | -73.639080 |
| BROOKLYN | 40.562493 | -73.774724 |
| MANHATTAN | 40.716458 | -73.865181 |
| QUEENS | 40.597138 | -73.613842 |
| STATEN ISLAND | 39.967678 | -72.991762 |
| All | 40.599550 | -73.686697 |
Melting (wide to long)
7.6. Combining¶
Row bind
pd.concat([bronx_crash, brooklyn_crash], axis = 0).head(5)
| CRASH DATE | CRASH TIME | BOROUGH | ZIP CODE | LATITUDE | LONGITUDE | LOCATION | ON STREET NAME | CROSS STREET NAME | OFF STREET NAME | ... | CONTRIBUTING FACTOR VEHICLE 2 | CONTRIBUTING FACTOR VEHICLE 3 | CONTRIBUTING FACTOR VEHICLE 4 | CONTRIBUTING FACTOR VEHICLE 5 | COLLISION_ID | VEHICLE TYPE CODE 1 | VEHICLE TYPE CODE 2 | VEHICLE TYPE CODE 3 | VEHICLE TYPE CODE 4 | VEHICLE TYPE CODE 5 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 10 | 01/01/2022 | 16:40 | BRONX | 10454.0 | 40.806107 | -73.917990 | (40.806107, -73.91799) | NaN | NaN | 520 EAST 137 STREET | ... | Unspecified | NaN | NaN | NaN | 4491478 | Sedan | Sedan | NaN | NaN | NaN |
| 18 | 01/01/2022 | 15:19 | BRONX | 10456.0 | 40.833750 | -73.900490 | (40.83375, -73.90049) | NaN | NaN | 1342 FRANKLIN AVENUE | ... | NaN | NaN | NaN | NaN | 4491440 | Taxi | NaN | NaN | NaN | NaN |
| 19 | 01/01/2022 | 15:00 | BRONX | 10453.0 | 40.858790 | -73.907364 | (40.85879, -73.907364) | AQUEDUCT AVENUE | BUCHANAN PLACE | NaN | ... | Unspecified | NaN | NaN | NaN | 4491694 | Station Wagon/Sport Utility Vehicle | NaN | NaN | NaN | NaN |
| 22 | 01/01/2022 | 18:21 | BRONX | 10466.0 | 40.890648 | -73.848750 | (40.890648, -73.84875) | EAST 233 STREET | GUNTHER AVENUE | NaN | ... | Unspecified | NaN | NaN | NaN | 4491488 | Sedan | Station Wagon/Sport Utility Vehicle | NaN | NaN | NaN |
| 29 | 01/01/2022 | 1:50 | BRONX | 10466.0 | 40.895718 | -73.849525 | (40.895718, -73.849525) | PITMAN AVENUE | WICKHAM AVENUE | NaN | ... | Unspecified | NaN | NaN | NaN | 4491166 | Station Wagon/Sport Utility Vehicle | Sedan | NaN | NaN | NaN |
5 rows × 29 columns
Also can use append() method.
bronx_crash.append(brooklyn_crash).tail(5)
/tmp/ipykernel_4287/939351689.py:1: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
bronx_crash.append(brooklyn_crash).tail(5)
| CRASH DATE | CRASH TIME | BOROUGH | ZIP CODE | LATITUDE | LONGITUDE | LOCATION | ON STREET NAME | CROSS STREET NAME | OFF STREET NAME | ... | CONTRIBUTING FACTOR VEHICLE 2 | CONTRIBUTING FACTOR VEHICLE 3 | CONTRIBUTING FACTOR VEHICLE 4 | CONTRIBUTING FACTOR VEHICLE 5 | COLLISION_ID | VEHICLE TYPE CODE 1 | VEHICLE TYPE CODE 2 | VEHICLE TYPE CODE 3 | VEHICLE TYPE CODE 4 | VEHICLE TYPE CODE 5 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 7645 | 01/31/2022 | 12:00 | BROOKLYN | 11220.0 | 40.640630 | -74.025734 | (40.64063, -74.025734) | 65 STREET | 2 AVENUE | NaN | ... | Unspecified | NaN | NaN | NaN | 4499700 | Station Wagon/Sport Utility Vehicle | Station Wagon/Sport Utility Vehicle | NaN | NaN | NaN |
| 7650 | 01/31/2022 | 8:30 | BROOKLYN | 11216.0 | NaN | NaN | NaN | NaN | NaN | 486 GATES AVENUE | ... | Unspecified | NaN | NaN | NaN | 4500316 | Sedan | Station Wagon/Sport Utility Vehicle | NaN | NaN | NaN |
| 7652 | 01/31/2022 | 10:12 | BROOKLYN | 11212.0 | 40.664436 | -73.922100 | (40.664436, -73.9221) | NaN | NaN | 699 RALPH AVENUE | ... | Unspecified | NaN | NaN | NaN | 4500537 | Station Wagon/Sport Utility Vehicle | Motorcycle | NaN | NaN | NaN |
| 7655 | 01/31/2022 | 21:50 | BROOKLYN | 11217.0 | 40.675250 | -73.973350 | (40.67525, -73.97335) | NaN | NaN | 209 LINCOLN PLACE | ... | Unspecified | NaN | NaN | NaN | 4500477 | Sedan | NaN | NaN | NaN | NaN |
| 7656 | 01/31/2022 | 9:40 | BROOKLYN | 11249.0 | 40.701130 | -73.960870 | (40.70113, -73.96087) | WYTHE AVENUE | WILLIAMSBURG STREET EAST | NaN | ... | Unspecified | NaN | NaN | NaN | 4500516 | Station Wagon/Sport Utility Vehicle | Box Truck | NaN | NaN | NaN |
5 rows × 29 columns
Column bind
mybronx = pd.merge(bronx_lat, bronx_long)
bronx_lat.shape
(948, 3)
bronx_long.shape
(948, 3)
7.6.1. Aggregation¶
mybronx.dropna()
| CRASH DATE | CRASH TIME | LATITUDE | LONGITUDE | |
|---|---|---|---|---|
| 0 | 01/01/2022 | 16:40 | 40.806107 | -73.917990 |
| 1 | 01/01/2022 | 15:19 | 40.833750 | -73.900490 |
| 2 | 01/01/2022 | 15:00 | 40.858790 | -73.907364 |
| 3 | 01/01/2022 | 15:00 | 40.858790 | -73.919550 |
| 4 | 01/01/2022 | 15:00 | 40.816550 | -73.907364 |
| ... | ... | ... | ... | ... |
| 1044 | 01/31/2022 | 15:00 | 40.886295 | -73.847916 |
| 1045 | 01/31/2022 | 10:32 | 40.819336 | -73.913700 |
| 1046 | 01/31/2022 | 16:00 | 40.815937 | -73.909134 |
| 1048 | 01/31/2022 | 14:58 | 40.868847 | -73.902626 |
| 1049 | 01/31/2022 | 6:50 | 40.851097 | -73.892810 |
1016 rows × 4 columns
mybronx.groupby('CRASH DATE')["LATITUDE"].median()
CRASH DATE
01/01/2022 40.837643
01/02/2022 40.859297
01/03/2022 40.837574
01/04/2022 40.831024
01/05/2022 40.865475
01/06/2022 40.830143
01/07/2022 40.840114
01/08/2022 40.844177
01/09/2022 40.843715
01/10/2022 40.857130
01/11/2022 40.842747
01/12/2022 40.854292
01/13/2022 40.850704
01/14/2022 40.847494
01/15/2022 40.845562
01/16/2022 40.846600
01/17/2022 40.865258
01/18/2022 40.833218
01/19/2022 40.850893
01/20/2022 40.841927
01/21/2022 40.836138
01/22/2022 40.859184
01/23/2022 40.859430
01/24/2022 40.826973
01/25/2022 40.841188
01/26/2022 40.842854
01/27/2022 40.847794
01/28/2022 40.847680
01/29/2022 40.859306
01/30/2022 40.843916
01/31/2022 40.841087
Name: LATITUDE, dtype: float64
for (date, group) in mybronx.groupby('CRASH DATE'):
print("{0:12s} shape = {1}".format(date, group.shape))
01/01/2022 shape = (36, 4)
01/02/2022 shape = (19, 4)
01/03/2022 shape = (26, 4)
01/04/2022 shape = (29, 4)
01/05/2022 shape = (47, 4)
01/06/2022 shape = (36, 4)
01/07/2022 shape = (54, 4)
01/08/2022 shape = (36, 4)
01/09/2022 shape = (26, 4)
01/10/2022 shape = (28, 4)
01/11/2022 shape = (32, 4)
01/12/2022 shape = (34, 4)
01/13/2022 shape = (33, 4)
01/14/2022 shape = (28, 4)
01/15/2022 shape = (42, 4)
01/16/2022 shape = (24, 4)
01/17/2022 shape = (27, 4)
01/18/2022 shape = (34, 4)
01/19/2022 shape = (29, 4)
01/20/2022 shape = (28, 4)
01/21/2022 shape = (32, 4)
01/22/2022 shape = (33, 4)
01/23/2022 shape = (24, 4)
01/24/2022 shape = (24, 4)
01/25/2022 shape = (21, 4)
01/26/2022 shape = (50, 4)
01/27/2022 shape = (35, 4)
01/28/2022 shape = (59, 4)
01/29/2022 shape = (60, 4)
01/30/2022 shape = (24, 4)
01/31/2022 shape = (40, 4)